Artificial intelligence inventions are moving fast, but patent writing still depends on one old rule: the invention has to be explained clearly. That sounds simple. In practice, it is where many AI patent applications become weak.
A lot of AI filings talk about “a model,” “a neural network,” or “machine learning” in a very broad way. They name the idea, but they do not explain enough about how the system is trained, how it makes decisions at runtime, what data it uses, how the data is prepared, and what technical effect the full system produces.
That gap matters. A patent specification is not a pitch deck. It is not a product page. It is not a research abstract. It is the document that has to carry the invention from filing to examination and, if needed, to enforcement.
For AI inventions, the quality of the specification often decides whether the patent becomes valuable or stays fragile.
This article explains how to draft a strong patent specification for AI with a close focus on training, inference, and data details. The goal is not to make the draft sound impressive. The goal is to make it useful, defensible, and broad in the right way. We will walk through what to include, how to describe it, where applicants often go wrong, and how to give patent counsel enough material to build claims that can survive pressure later.
Why AI patent specifications need a different level of detail
AI inventions often fail in drafting for a very basic reason. The people closest to the invention know the system too well. Because they understand it, they leave out the parts that feel obvious to them.
They say the model is trained on historical data. They say the engine generates a prediction. They say the output improves performance. Inside the company, everyone nods because everyone already knows what those words mean in context.
A patent examiner does not live inside that context. Neither does a judge. Neither does a competitor trying to design around the patent. The patent has to create its own context from the ground up.
In many software areas, broad functional language can still carry some weight if the technical architecture is explained elsewhere in the document.
In AI, vague drafting becomes dangerous very quickly because so much of the invention may depend on the details of how data is formed, how labels are created, how a model is trained, how inference is constrained, how outputs are filtered, and how system performance changes as a result.
That does not mean every AI patent must disclose source code or every hyperparameter. It means the specification should explain enough of the real mechanism so that the invention sounds like an engineered system, not a wish.
A strong AI patent specification does three things at once. It shows what problem the invention solves. It shows how the system solves that problem. And it gives enough variation around the core idea that the claims can later be written with both precision and room to maneuver.
This is especially important because AI inventions are often attacked from multiple directions. One challenge says the claims are abstract.
Another says the invention was not enabled across the full scope. Another says the filing only described a result, not the way to achieve the result. Another says the core step was conventional. The specification is where you begin building the response to all of those issues.
The real job of the specification in an AI patent
Many founders and product teams think of the patent claims as the main event and the specification as background material. That is backward. The claims matter, but the specification is the foundation that supports everything else.
The specification is where you preserve technical options before they disappear. It is where you capture alternate training approaches before the product team changes direction. It is where you explain why a particular data pipeline matters. It is where you connect the training process to runtime behavior. It is where you avoid getting boxed into one model type, one feature set, or one deployment setting.
In AI work, products evolve fast. The model version used today may be replaced next quarter. The training dataset may be expanded or cleaned. The inference pipeline may move from cloud to edge.
Latency constraints may change. Fine-tuning may replace a hand-built model. Retrieval may be added. Human review may shift from before output to after output. A weak specification freezes one moment. A good one captures the invention at a deeper level so the patent remains useful even when the implementation changes.
That is why patent drafting for AI should not start with the label of the model. It should start with the technical workflow.
What enters the system? What processing happens before training? What representation is built? What objective is optimized? What happens during runtime? What data or signals are used then? What output is produced? How is that output constrained, verified, ranked, or transformed? What measurable technical benefit comes from the full approach?
These are the questions that turn an AI idea into patent-grade disclosure.
Before drafting: identify the invention correctly
One of the biggest mistakes in AI patent work happens before anyone writes a word. The wrong invention gets selected.
A team might say, “Our invention is using AI to classify documents.” That is usually too high-level. Another team might say, “Our invention is a transformer model.” That is usually too narrow and often not the invention at all. Another might say, “Our invention is a prompt.” That may be part of the picture, but often not enough on its own.
The better question is this: what is the technical thing your system does differently that changes how results are achieved?
Sometimes the invention is in training. Maybe the model learns from weak labels generated from system logs, then uses confidence-weighted loss adjustment to reduce noise.
Sometimes the invention is in inference. Maybe the system uses runtime sensor state to select one of several specialized models, which reduces latency while keeping prediction quality above a threshold. Sometimes the invention is in the data pipeline.
Maybe the system builds a multi-view representation by joining structured records, images, and time-based event sequences in a way that improves failure prediction accuracy in industrial equipment.
Sometimes the invention is in the loop between these stages. Maybe feedback from live inference is turned into curated re-training examples under a rule set that limits drift.
The label “AI” is not the invention. The invention is the specific technical design.
When you identify the invention correctly, the specification becomes easier to write. The training section, the inference section, and the data section stop feeling like separate boxes and start reading like parts of a single system.
The best AI specifications tell a technical story

A good patent specification has structure, but it also has movement. It should take the reader from problem to mechanism to result.
For an AI invention, that story often looks like this:
There is a practical technical problem in a real environment. Existing systems fail because they rely on fixed rules, poor data quality, delayed output, excessive compute, weak personalization, unstable model behavior, or some other real limitation.
The disclosed system addresses that limitation by preparing data in a certain way, training one or more models under a defined process, and executing inference under runtime conditions that produce better technical results.
The system may also include post-processing, feedback, monitoring, model selection, thresholding, or human-in-the-loop steps. The result is a system that performs better in a measurable and operationally meaningful way.
That story matters because it keeps the draft grounded. If the specification only says the model predicts better, it can feel empty. If it explains why older systems failed, what pipeline changes were introduced, and how those changes affect runtime behavior, the invention becomes much more concrete.
This is one reason simple language is powerful in patent drafting. Simple language forces clarity. It makes gaps visible. If you cannot explain the invention in plain words, the patent is probably not ready.
Start with the technical problem, not with AI buzzwords
In the background and summary portions of the draft, avoid opening with generic statements like “machine learning has many uses in modern systems.” That does not help much. It sounds broad, but it adds little value.
Instead, describe the actual technical pain point.
Maybe a fraud detection system produces too many false positives because transaction patterns change quickly and static rules lag behind. Maybe a medical imaging workflow requires large human review time because current detection systems do not incorporate prior scan history.
Maybe an industrial monitoring system misses early signs of equipment failure because separate sensor streams are processed independently rather than as a unified time sequence. Maybe a search engine returns stale or generic answers because relevance scoring does not use recent user interaction patterns.
When the problem is real and specific, the rest of the draft becomes sharper. The training section can explain how the model is built to address that issue. The inference section can explain how runtime decisions differ from older systems. The data section can explain why the selected data sources and preprocessing steps matter.
Examiners respond better to a system that solves a technical problem than to a filing that merely says AI is used for a known task.
This does not mean the background should admit too much prior art. It means the draft should frame the problem carefully and technically. You are not writing a confession. You are writing context.
Do not treat training, inference, and data as separate silos
Many AI patent drafts lose power because they break these topics apart too sharply. They have one paragraph on training, one paragraph on inference, and a short note saying “training data may be collected from one or more sources.” That kind of structure looks complete on paper, but it misses the interaction between the stages.
In real AI systems, these stages depend on each other.
The way data is cleaned affects the labels. The labels affect training stability. The training approach affects what signals are available during inference. The runtime environment affects what kind of model compression or specialization is needed. The output logs from inference may become new training examples. The feedback loop may be where much of the inventive value lives.
A stronger specification makes those links visible.
For example, if a system trains a model using paired sensor data and maintenance records, then during runtime uses the same sensor channels plus current operating mode to estimate failure probability, the connection between training and inference should be explicit.
If the training process creates embeddings for support tickets and product logs, then the runtime system uses those embeddings for retrieval and response generation, that continuity should be explained. If training uses synthetic augmentation to handle rare events, and inference includes confidence gates for similar rare-event cases, the draft should show that relationship.
A patent becomes more convincing when the reader can see the full pipeline working together.
How much training detail is enough
This is one of the most common questions in AI patent work. Inventors worry that too much training detail will narrow the patent. Lawyers worry that too little training detail will make the disclosure weak. The right answer is not to choose one or the other. The right answer is layered disclosure.
You want to explain training in enough detail that the reader understands the technical design, while also disclosing alternatives so the invention is not locked to one exact implementation.
A strong training disclosure often covers the purpose of training, the nature of the input data, the target output or labels, the model architecture at an appropriate level, the training objective or learning approach, the way training examples are formed, any noteworthy preprocessing or feature generation, any special sampling or balancing logic, any feedback or retraining loop, and the technical result of that training design.
Not every invention needs every one of those items. But most good AI specifications cover several of them.
For example, saying “the model is trained using historical data” is weak. Saying “the model is trained using time-ordered event records derived from user device interactions, where records from a defined time window are aggregated into session-level training examples and labeled based on a later-confirmed device state transition” is much stronger. It gives shape to the process. It tells the reader what the examples look like, where the labels come from, and how time matters.
You do not always need to disclose exact numerical settings. But if a threshold, weighting strategy, batching rule, or loss function choice is central to the invention, describe it. And if there are viable alternatives, describe those too.
The key is this: explain the training process as an engineered method, not as a magical black box that somehow becomes accurate.
Describing training data without giving away trade secrets

Some teams hold back too much because they fear disclosing proprietary datasets. That concern is understandable. But many AI patent filings become weak because the data section says almost nothing.
You usually do not need to disclose every record, every source file, or every customer-specific detail. What you do need is enough description to show the role and character of the data.
That means you should explain the categories of data, the structure of the data, the origin of the data at a useful level, the timing of collection if it matters, the label generation approach if there are labels, and the transformations applied before training.
For example, you may describe the data as structured transaction records, image frames captured from a device-mounted camera, audio clips segmented from call recordings, server log events, system telemetry from industrial equipment, medical records with de-identified outcomes, or user interaction sequences from an application. If the invention depends on combining multiple forms of data, say that clearly. If the value comes from generating training examples by aligning records from different times or systems, explain that.
Patent value often comes from the data handling insight, not just the model.
Suppose the invention uses maintenance logs and vibration sensor streams to predict machine failure. If the clever part is aligning free-text maintenance notes with sensor windows to create labeled examples for rare fault modes, the specification should not hide that. That may be the heart of the patent.
The trick is to disclose the mechanism, not the secret sauce in raw form. You can describe categories, flows, mappings, and transformations without attaching the full dataset.
Data provenance matters more than many teams realize
A patent examiner may not use the phrase “data provenance,” but the concept matters in AI drafting. The source and path of the data often shape whether the invention sounds real.
If the patent says the model uses “training data,” that does not say much. If it explains that the training data is collected from endpoint device logs, support ticket metadata, system configuration histories, and user correction events, and that those are joined using a device identifier and time alignment rule, the system feels much more grounded.
This matters for at least three reasons.
First, it helps show enablement. A reader can understand how training examples are actually built.
Second, it helps distinguish from prior art. Many prior systems may use machine learning generally, but not the same input mix or same mapping between sources.
Third, it helps support claims around data preparation, feature generation, and system architecture. Those can become important fallback positions later.
A lot of inventive work in AI happens before model training even begins. If the patent skips that part, it may skip the most patentable layer of the system.
How to write about labels and targets
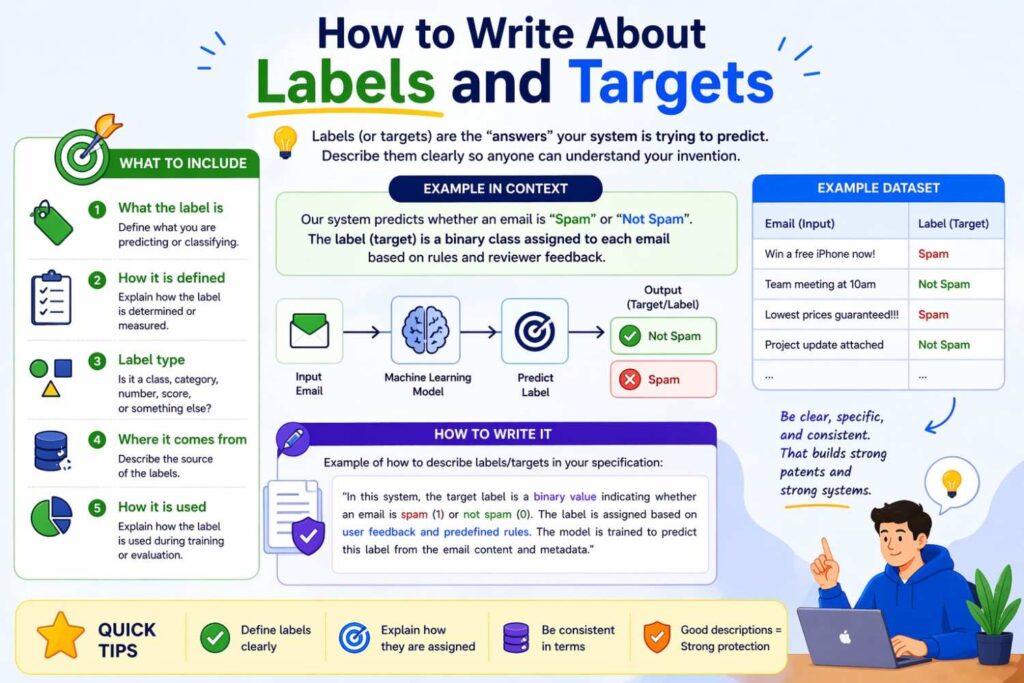
In AI systems, labels are often where the invention hides in plain sight.
Some teams assume labels are boring because they are just the answer field used during training. In practice, label creation can be very inventive. Maybe labels are weak labels built from delayed user actions.
Maybe they are generated from expert review plus automated screening. Maybe they are derived from threshold crossings in sensor data. Maybe they are inferred from downstream events that occur hours later. Maybe several noisy signals are combined to produce a probabilistic target.
If label creation is novel or important, the specification should treat it as a major technical feature.
Explain where the labels come from. Explain when they are generated. Explain whether they are binary, multi-class, continuous, ranked, or structured. Explain whether they are direct measurements or inferred outcomes. Explain whether they are human-provided, machine-generated, or hybrid. Explain whether confidence values are attached.
This is especially important in modern AI where perfectly labeled data is rare. Many high-value systems use weak supervision, semi-supervised learning, active learning, reinforcement signals, preference data, or self-generated pseudo-labels. These are not side notes. They are core parts of how the invention works.
A patent that only says “the model is trained on labeled data” throws away a major chance to define the invention more deeply.
Explain feature generation like it matters, because it does
Teams often focus on model architecture because it sounds advanced. Yet in many real systems, the feature generation process is more inventive and more durable than the exact model type.
A model may change over time from gradient boosting to a neural network or from one deep architecture to another. But the way raw data is transformed into meaningful input often stays closer to the business and technical value of the system.
If the invention uses windowed statistics over sensor signals, graph-based relations between entities, embedding representations for text, image patches linked to metadata, or context vectors formed from recent user sessions, say so. If the system creates derived inputs from multiple time horizons, explain that. If it converts raw logs into state transition features or computes deviation scores against learned baselines, explain that too.
The specification should make clear whether features are handcrafted, learned, generated by another model, or some mix of those approaches.
Do not treat feature generation as just a prelude. In many AI patents, that layer is where the technical insight lives.
Model architecture: be specific enough, but do not trap yourself
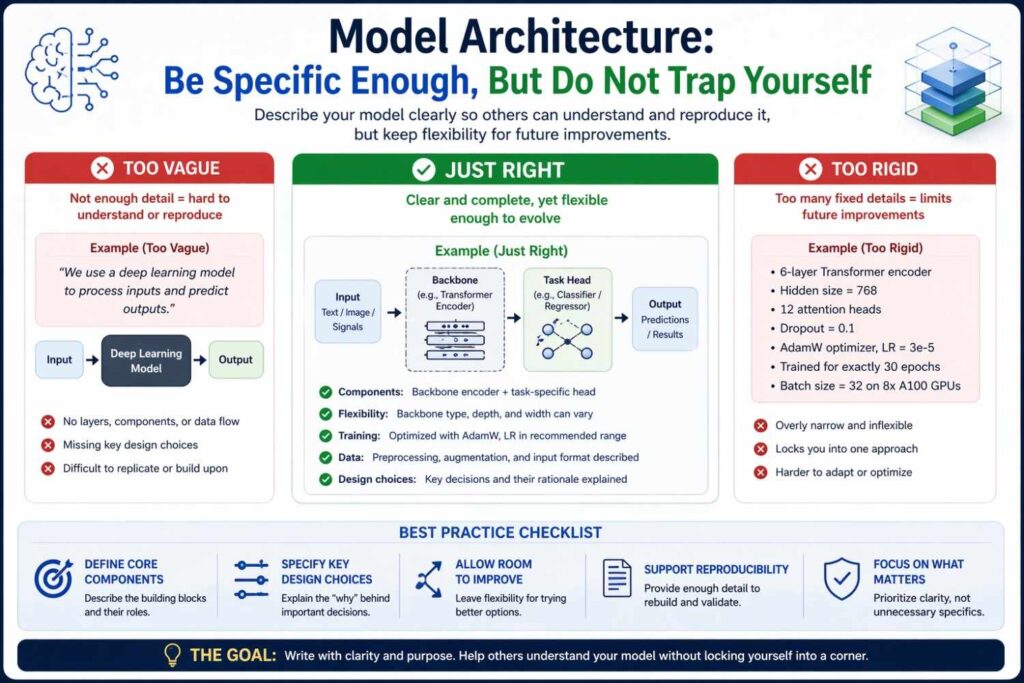
There is a natural tension in AI drafting around architecture. If you say too little, the patent feels abstract. If you say too much, the patent may seem limited to one model type.
The answer is to describe the architecture at multiple levels.
At a broad level, explain the class of model or models that can be used. This might include neural networks, decision tree ensembles, support vector machines, probabilistic models, sequence models, graph models, or combinations of these.
At a more specific level, explain the architecture used in one or more implementations. This might include convolutional layers for image regions, recurrent layers or attention layers for time-based inputs, encoder-decoder structures for translation tasks, multimodal fusion layers for mixed inputs, or retrieval-augmented pipelines for grounded text generation.
Then connect the architecture choice to the technical problem. Do not just name the model. Explain why it is used.
For instance, if a sequence model is used because event order carries predictive meaning, say that. If a graph model is used because relations among devices or users matter, say that. If a compressed student model is used at runtime because edge deployment requires low memory and fast execution, say that. Architecture becomes far more meaningful when it is tied to the problem being solved.
You should also disclose variations. Say that other models may be used to perform similar functions or that individual modules may be substituted. This creates useful room later when claims are drafted or amended.
Training objectives, losses, and optimization details
You do not need to turn the patent into a research paper full of equations unless the invention truly depends on that level of detail. But if the training objective is part of the invention, it should be described with care.
Maybe the model is trained to minimize a weighted loss that places more weight on false negatives for rare safety events. Maybe contrastive learning is used to bring related records closer in embedding space.
Maybe a ranking loss is used because the task is not simply classification but prioritization. Maybe the system uses a composite objective that balances prediction quality, calibration, and latency-aware constraints. Maybe knowledge distillation is used to move behavior from a large teacher model to a smaller runtime model.
These choices can be highly relevant to patentability because they define how the model learns, not just what result it produces.
The best way to write these sections is in plain language first. Explain what the training objective is trying to accomplish. Then explain the mechanism at a moderate technical level. Then mention variants.
For example, you might say the training process penalizes incorrect predictions more heavily for underrepresented classes to reduce bias toward common events. That is a clear statement of purpose. You can then add that class weights may be assigned based on inverse frequency, empirical risk, or a defined cost function. That gives useful technical range without burying the reader.
Sampling, balancing, and rare-event handling
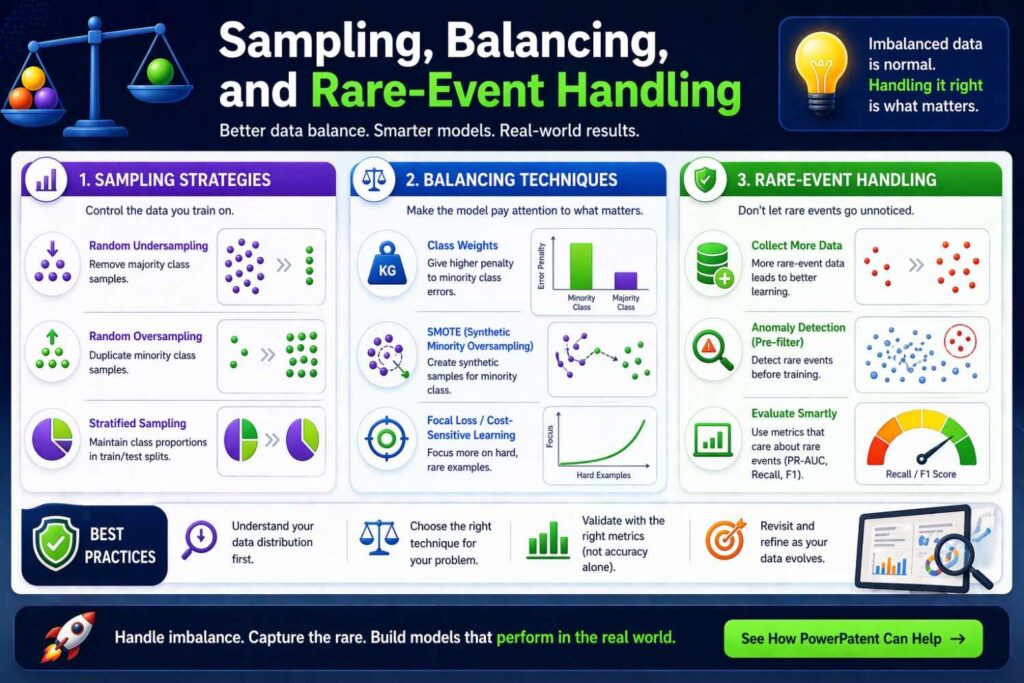
Many real AI systems break down because important outcomes are rare. Fraud is rare. Device failures are rare. Severe safety incidents are rare.
Certain medical findings are rare. A weak patent ignores this and simply says the model is trained on historical examples.
A better patent explains how the training process deals with imbalance.
Maybe positive examples are oversampled. Maybe negative examples are downsampled by cluster. Maybe hard negatives are selected based on confusion with prior model versions.
Maybe rare classes are augmented using synthetic transformations. Maybe the system trains separate specialist models for common and rare cases. Maybe it uses a two-stage process where a coarse detector finds candidates and a second model refines predictions.
These are not minor implementation details when they affect practical success. They can make the difference between a generic AI filing and a patent that reflects real engineering work.
If rare-event handling is part of the system’s novelty or technical advantage, give it room in the specification. Describe why the problem exists and how the training process addresses it.
Validation, testing, and model selection in the specification
Many patent drafts skip validation entirely, as if the model simply emerges from training and is ready to deploy. That can make the system sound incomplete.
A useful specification may include model validation and selection logic where relevant. This is especially true if the invention involves choosing among candidate models, selecting thresholds, calibrating confidence, or tailoring models to different deployment settings.
For example, the system may train several candidate models and select one based on precision at a target recall, latency within a compute budget, calibration error below a threshold, or performance on a device-specific validation set.
It may use temporal holdout data to avoid leakage from future events. It may tune decision thresholds differently across environments. It may select among specialized submodels based on deployment region, hardware profile, or input quality.
These details matter because they reinforce that the invention is a working system, not just a training experiment.
If model selection contributes to the technical result, say so clearly.
Retraining, continuous learning, and feedback loops
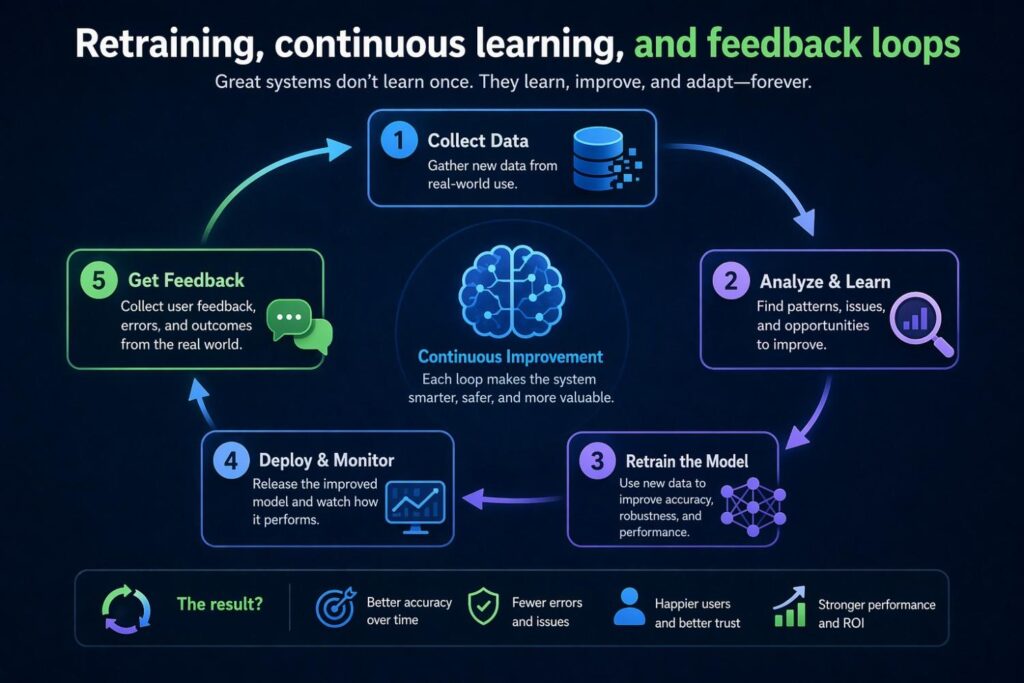
Modern AI systems often do not stop learning after the first training cycle. They ingest new data, capture corrections, detect drift, and retrain or adapt. If the invention includes that lifecycle, the specification should reflect it.
This does not mean every patent should claim continuous learning broadly. It means you should disclose the feedback path if it is technically important.
For instance, runtime outputs may be logged with confidence values and later matched to verified outcomes. User corrections may be filtered to remove low-quality feedback before creating new training examples.
A drift detection module may compare feature distributions between training and live traffic. A retraining pipeline may be triggered when error rates pass a threshold or when new categories appear. In some systems, human review decisions become curated labels for model refinement. In others, a large model may generate candidate labels that are then checked by rules or experts before use.
These flows can be highly inventive, and they also help support claims around system maintenance and model improvement over time.
A patent that only covers initial training may miss a major part of the commercial moat.
Inference is not just “the model outputs a result”
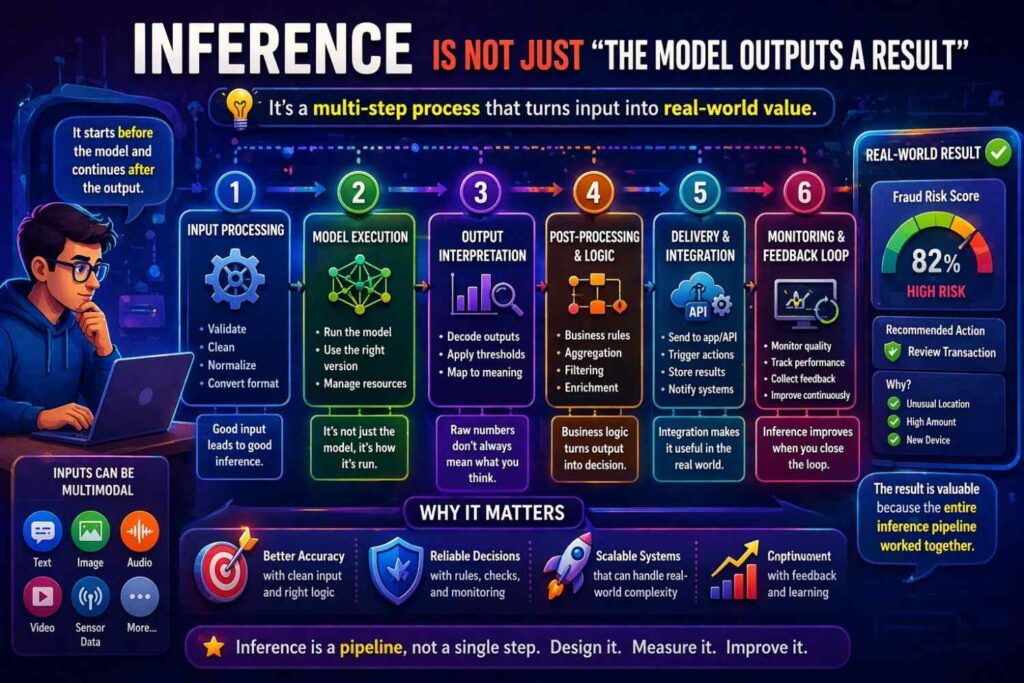
Inference is often the most neglected part of AI patent drafting. Many applications describe training with some care, then reduce runtime behavior to one sentence.
That is a mistake because runtime operation is where the invention meets the world.
Inference is where latency matters. It is where hardware constraints appear. It is where confidence thresholds matter. It is where model routing happens. It is where input normalization has to work under messy live conditions. It is where outputs may need ranking, filtering, grounding, or verification. It is where user context may change the behavior of the system. It is where edge cases are handled.
A strong AI patent specification treats inference as a rich technical stage.
You should explain what data is received at runtime, what preprocessing happens then, which model or module is invoked, how runtime context affects execution, what output is produced, and what post-processing occurs before that output is used or shown.
If the invention depends on a two-stage inference flow, say so. If runtime metadata selects a specialized model, say so.
If outputs are calibrated or checked against business rules, say so. If the model runs on-device and a server-side model handles exceptions, say so. If the system retrieves reference data and combines it with model output, say so.
Inference details often provide some of the strongest support for claims that look less abstract and more technical.
Runtime preprocessing and input conditioning
Live inputs are messy. They arrive incomplete, noisy, delayed, and out of order. A specification that ignores this can sound detached from real deployment.
If runtime preprocessing is important, explain it. The system may normalize values, fill missing fields, generate a window over recent events, tokenize text, align sensor streams, convert images to a target format, compute embeddings, remove duplicate records, or create context summaries from recent interactions.
In some inventions, this runtime conditioning is part of the technical contribution. A model may perform well because the system creates a special runtime representation that was designed to match the way training examples were formed. Or the runtime logic may compensate for data quality issues that training alone cannot solve.
For example, a health monitoring system may align incoming wearable sensor data with the patient’s recent medication events before passing the sequence to a model.
A customer support classifier may create a combined representation from the current message, prior thread history, and account state. An autonomous system may fuse camera, radar, and map context into a shared input structure before running prediction.
These details should not be hidden in a vague sentence like “the input may be preprocessed.” Explain the actual role of preprocessing in the system.
Model selection and routing during inference
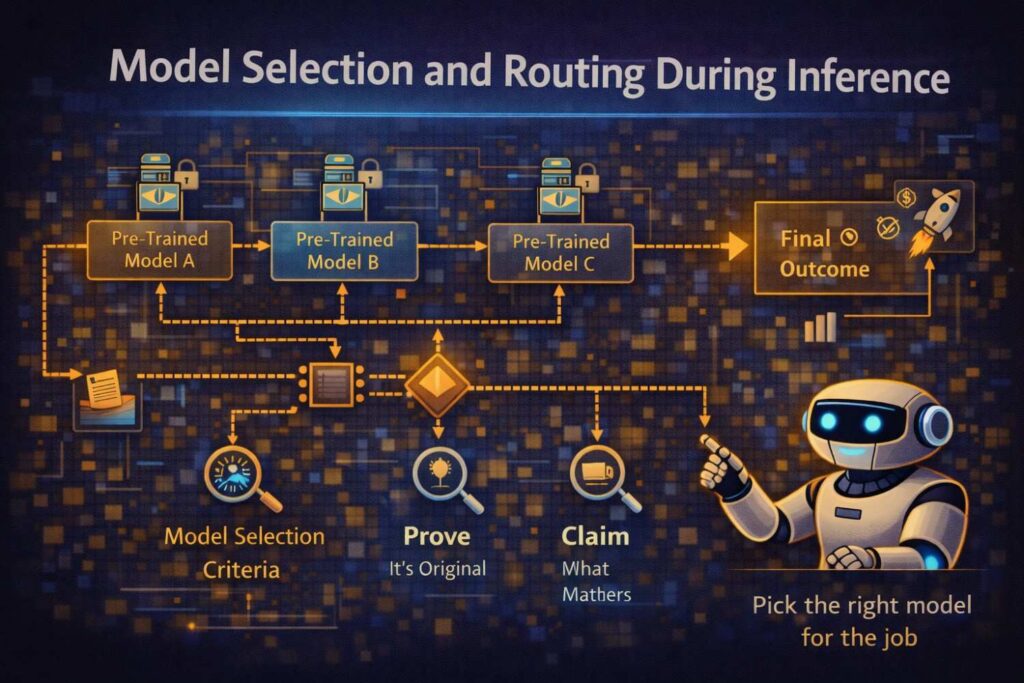
A lot of AI systems today do not use one single model for all runtime cases. They route inputs.
Maybe a lightweight model handles routine cases and a heavier model handles uncertain cases. Maybe language, region, or device type determines which model is selected. Maybe a first model detects the input category and passes the input to a specialist submodel. Maybe a policy engine decides whether local inference is enough or whether a cloud model should be used. Maybe a retrieval score determines whether generative output is allowed or whether the system falls back to a rules-based answer.
This kind of inference routing is often patent-worthy if it solves a real technical problem such as latency, compute cost, privacy, or quality variation across inputs.
If routing is part of the invention, explain the selection logic. Explain what signals are used. Explain when routing happens. Explain the technical reason for it. Explain how the chosen model behaves differently.
This adds depth to the specification and creates useful support for claims that cover orchestration, not just prediction.
Confidence, uncertainty, and thresholding
Not all outputs should be treated equally, and good AI systems know that. Many important inventions include some way of handling uncertainty at inference time.
The model may output a confidence score, probability, margin, rank score, uncertainty estimate, calibration value, or other reliability signal. That signal may then control what happens next.
High-confidence outputs may be applied automatically. Lower-confidence outputs may be flagged for review, combined with additional evidence, or sent through a different path.
A patent specification should capture this if it matters to the technical design.
For example, a defect detection system may only trigger equipment shutdown if confidence exceeds a threshold and if a second sensor-based rule is also satisfied.
A recommendation engine may vary the number of suggestions shown based on certainty. A document processing system may send uncertain fields to a human verifier while automatically filling the rest. A generative system may suppress unsupported answers when retrieval grounding falls below a score.
These details help show that the system is built for real operation, not just lab accuracy.
Post-processing is often part of the invention
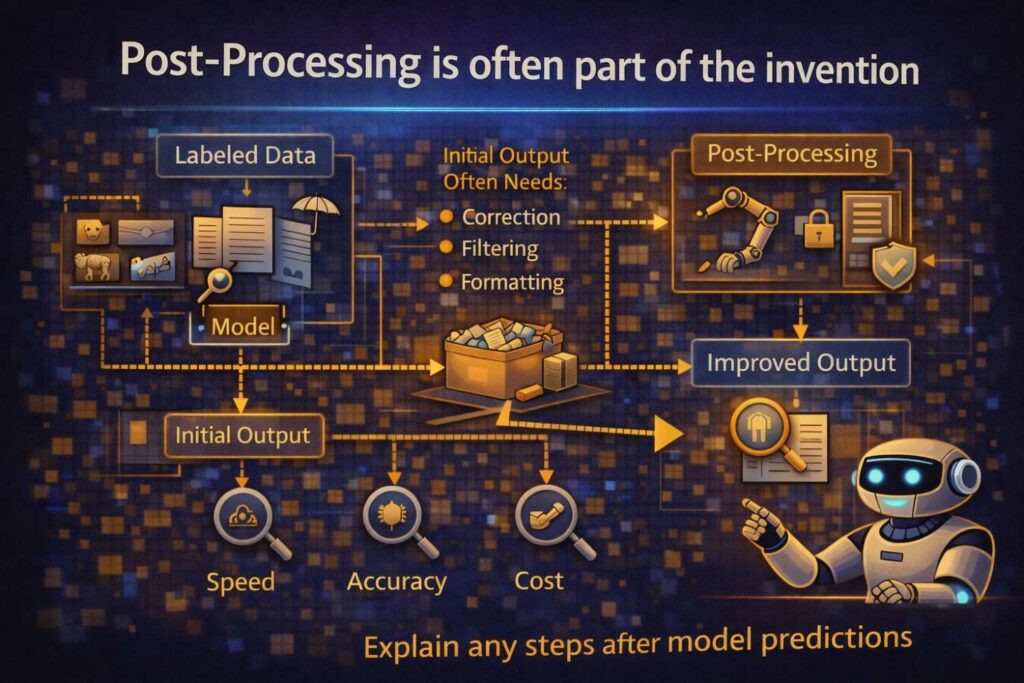
In AI systems, the raw model output is frequently not the final output. There may be ranking, aggregation, filtering, formatting, constraint enforcement, reconciliation with external data, or conversion into control signals.
This post-processing stage can be extremely important in patents because it is often where the model becomes a practical system.
Suppose a model predicts likely machine faults, but the system then groups overlapping fault predictions, ranks them by urgency, and generates a maintenance schedule.
Or a text generation system drafts an answer, but a post-processor checks citations, removes unsupported claims, and rewrites the answer into a policy-compliant format. Or an image model identifies regions of interest, but a downstream module maps those regions into device control commands.
If these transformations matter, disclose them clearly.
A patent that stops at “the model generates an output” may miss the most business-critical stage of the workflow.
Explain the deployment environment
AI does not run in empty space. The hardware and software environment often matters.
Does inference occur on a mobile device, a vehicle control unit, a wearable device, a server, a distributed edge network, or a hybrid system? Is training done centrally and inference done locally? Are there memory limits, battery limits, bandwidth limits, or privacy limits? Is model compression used? Is batching used? Is the runtime system asynchronous? Does the system use specialized accelerators?
These points can strengthen the technical character of the patent and help frame the invention as a practical computing solution.
For example, if the invention reduces inference latency on low-power devices by selecting a compressed model and using a selective fallback policy, that should be described.
If the system preserves privacy by extracting features locally and sending only derived representations to a remote service, say that. If the system maintains response quality under unstable connectivity by caching embeddings or local reference data, explain that too.
Deployment details can be critical in AI patents because they connect model design to real-world system constraints.
Data details: where many AI patents quietly rise or fall

Now let us focus more directly on data, because this is the area many teams underwrite.
People often think model architecture is the impressive part and data is just fuel. In real patent work, data handling is often the more durable source of advantage.
A company can switch model families. It can fine-tune a better backbone next year. But the data pipeline that creates useful training and inference inputs is often much harder for others to copy.
That pipeline may include acquisition, joining, cleaning, segmentation, windowing, labeling, augmentation, balancing, filtering, versioning, privacy handling, storage, retrieval, and conversion into representations used by models. If that full path is skipped in the patent, a great deal of the invention may be lost.
A strong specification should explain not just that data exists, but how it becomes useful.
What raw records are received? How are they validated? How are missing values handled? How are records linked across systems? How are time windows defined? How are examples split? How are noisy sources filtered? How are training and validation sets separated to avoid leakage? How are live inputs matched to training format? How are data updates handled after deployment?
These are practical questions, and answering them makes the patent stronger.
Data cleaning and normalization should not be treated as routine by default
Some drafting teams assume data cleaning is always conventional and not worth mentioning. Sometimes that is true. Often it is not.
If the invention depends on specific cleaning or normalization logic, include it.
Maybe the system normalizes values differently depending on sensor type. Maybe outlier removal uses context-aware thresholds rather than global ones. Maybe duplicate records are resolved by a confidence-based merge. Maybe free-text fields are standardized using a domain dictionary before embedding. Maybe image inputs are corrected based on device metadata. Maybe event timestamps from different systems are aligned to a common reference clock.
These steps can make or break model performance, and in some inventions they are part of the novelty.
The phrase “the data may be cleaned” does almost nothing. The specification should explain the cleaning approach where it carries technical importance.
Temporal structure in data is often central
Many AI inventions involve time, but patents often flatten time away.
If the system learns from or predicts based on sequences, windows, histories, delays, or time gaps, the specification should say so clearly. Sequence order, event frequency, dwell time, lag between signal and outcome, and recent-versus-long-term behavior can all matter.
For example, a churn model may gain its value not from the use of AI generally but from forming training examples from rolling windows and separating short-term changes from long-term baseline behavior.
A machine failure model may depend on the order in which sensor anomalies appear. A medical model may compare current images with prior scans. A fraud system may use transaction bursts over defined intervals. A support system may rank solutions based on recent problem clusters.
If time matters, write about it as part of the invention, not as a casual detail.
Multimodal data deserves careful treatment

Many modern AI systems use more than one data type. Text plus image. Audio plus text. Sensor data plus logs. Structured tables plus free text. User history plus live context.
Multimodal systems often contain very patentable design decisions because combining different types of signals is not trivial. The invention may lie in how the signals are aligned, which representations are formed, when fusion occurs, whether one mode is used to filter another, or how missing modalities are handled.
If the system is multimodal, the specification should explain the role of each mode. What does each contribute? Are they processed separately at first? When are they combined? Is there an attention or weighting mechanism? What happens if one source is missing or low quality? Are some modes used only in training, while others are available at inference?
These details make the patent much more robust. Without them, the filing may read like a generic statement that “multiple types of data may be used.”
Synthetic data, augmentation, and simulation
These topics matter more and more in AI patents. Sometimes real-world data is scarce, expensive, private, or unbalanced. Teams then use synthetic data, augmented samples, or simulated environments.
If that practice is part of the invention, the specification should explain it properly.
Perhaps rare defect images are simulated to improve coverage. Perhaps speech examples are augmented with noise profiles matching deployment conditions. Perhaps a robotics system learns from simulated trajectories and then adapts to real sensor conditions. Perhaps tabular records are augmented to represent unusual combinations that are underrepresented in historical data. Perhaps synthetic prompts and responses are generated to fine-tune a support assistant, but only after being filtered using domain rules.
These are not trivial add-ons when they directly affect training quality or deployment readiness.
A useful patent should explain what synthetic or augmented data is generated, why it is generated, how it is used, and what guardrails apply to avoid drift or unrealistic samples.
Privacy, security, and governance around data
For many AI products, data cannot be discussed without addressing privacy and security. These issues are not just policy concerns. They can be technical features of the invention.
Maybe the system trains using de-identified data and stores lookup mappings separately. Maybe sensitive fields are transformed into embeddings locally before transmission. Maybe federated learning is used to avoid raw data movement. Maybe the system uses secure enclaves for model execution. Maybe gradient updates are filtered or clipped. Maybe access controls govern which training subsets can be used for which tasks.
If those technical choices are relevant to the invention, disclose them.
This can be especially important when the invention solves a tension between accuracy and privacy, or between centralized learning and local data restrictions. Patents that explain how the system handles that tension can be much stronger and more commercially meaningful.
Generative AI needs even more care in the specification
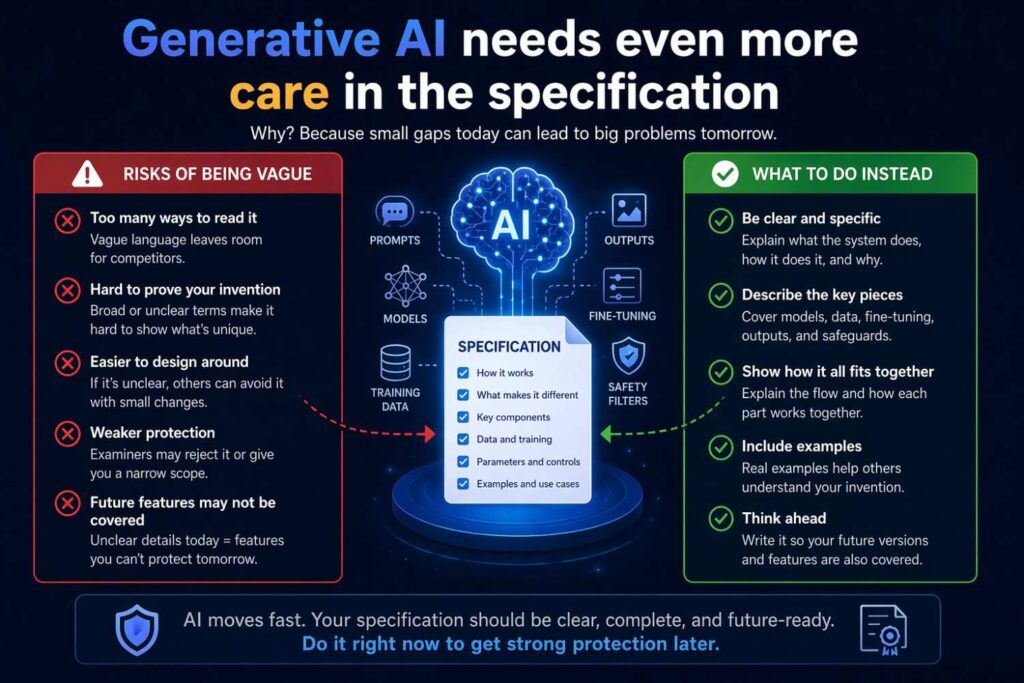
Generative AI filings often sound polished but empty. They talk about prompts, responses, and large models in broad terms, but they do not explain enough of the technical workflow.
If the invention involves generative AI, the same core principles still apply. Explain training, inference, and data details with care. But also go further where needed.
What model or model family is used? Is it pre-trained, fine-tuned, instruction-tuned, or adapted using retrieval? What training data or fine-tuning data is used? How are examples created? Are prompts templated or constructed dynamically? Does inference include retrieval from a knowledge store? How are retrieved passages ranked or filtered? Does the system ground outputs in source materials? Are hallucinations reduced by verification steps? Are outputs constrained by policy, schema, or domain logic? Is the system selecting among multiple prompt forms or models at runtime? Is user feedback captured for later refinement?
These questions matter because generative systems are easy to describe loosely and hard to patent well unless the underlying mechanism is explained.
A generic statement that a language model generates an answer is not enough. The specification should explain what makes this system technically different and useful.
Retrieval-augmented systems and knowledge grounding
Many important AI systems now combine model generation with retrieval. This is a rich area for patent drafting because the inventive value may lie in the retrieval logic, the query formation, the ranking method, the context construction, the grounding checks, or the feedback loop.
If the system uses retrieval, explain the full path.
How is the query built? Does it use the current request only, or also user state, prior interactions, device data, or domain metadata? What repository is searched? How are documents chunked, indexed, or embedded? How are candidates ranked? How are retrieved items inserted into model context? Are only high-confidence passages used? Is there a post-generation verification step that checks whether generated statements are supported by retrieved evidence?
These details can turn a broad “AI assistant” filing into a serious patent asset.
Do not hide the technical effect
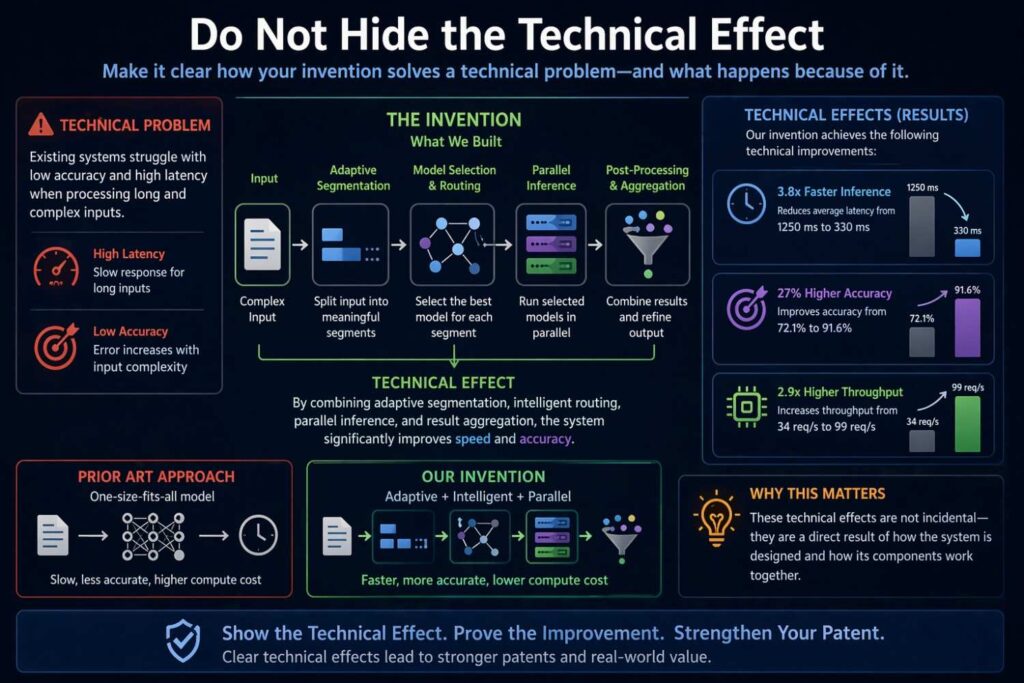
Patent specifications for AI often spend pages on architecture and still fail to clearly state the technical effect. That is a problem.
What actually gets better because of the disclosed approach?
Maybe inference latency drops. Maybe false positives fall. Maybe recall improves for rare events. Maybe bandwidth use is reduced. Maybe model drift is detected earlier. Maybe device battery life improves because only selected models run locally. Maybe human review time is reduced because uncertain fields alone are escalated. Maybe generated content becomes more reliable because unsupported outputs are suppressed.
A specification should state these effects in plain words and tie them to the disclosed mechanism.
Do not just say the system improves performance. Say what performance changes and why.
This helps with examination and also makes the draft more useful later for litigation, licensing, or product alignment.
Examples are not optional in AI patents
A lot of AI patents stay too abstract because no one wants to commit to an example. That is a mistake. Examples make the disclosure believable and useful.
A good specification usually includes one or more worked examples or implementation scenarios. These do not have to be narrow. They simply need to show the invention in action.
For instance, an example may describe a fraud system that collects transaction records, device fingerprints, login histories, and chargeback outcomes; forms session-based examples; trains a model using weighted loss for rare fraud events; then at inference uses current transaction data plus recent session activity to score risk and route uncertain cases for review.
Another example may describe a medical imaging workflow where prior scan embeddings are paired with current scan regions and clinical history, a ranking model is trained to prioritize suspicious findings, and inference produces ranked review queues that reduce reading delay.
Examples can be short or long, but they should connect the components of the system into a complete path.
This is one of the most effective ways to make an AI patent specification stronger.
Claim support begins in the specification

Even if you are focused right now on the specification rather than the claims, you should draft with future claims in mind.
For AI inventions, claim support can come from many layers. The system as a whole. The data preparation pipeline. The method of creating labels. The training process. The runtime inference flow. The model routing logic. The confidence handling. The post-processing. The feedback loop. The deployment architecture. The privacy-preserving mechanism.
If the specification only describes one of those layers, the claim set later may be thinner than it should be.
A smart draft gives room for several claim strategies. It may support claims that focus on a computer-implemented method, claims that focus on a system, claims that focus on a non-transitory computer-readable medium, and dependent claims that drill down into training data formation, runtime thresholds, feature generation, or multimodal fusion.
This is another reason broad but empty language is not helpful. It does not provide real fallback positions.
How to avoid sounding too narrow while still being concrete
Founders often fear that detail narrows the patent. Sometimes it can, but vagueness creates a different and often worse problem: the patent does not support enough later.
The solution is not to avoid detail. The solution is to draft detail with variation.
Describe one implementation clearly. Then disclose alternatives. Use phrases that indicate examples rather than absolute limits. Explain that certain modules may be substituted, reordered, combined, or omitted in different implementations. Identify multiple categories of input data, multiple model types, multiple training approaches, and multiple deployment settings where appropriate.
For example, you might explain one embodiment using a transformer encoder over event sequences, then state that other sequence-processing models may be used, including recurrent networks or temporal convolution models. You might explain that labels can come from expert review in one implementation and delayed outcome events in another. You might explain that inference may occur fully on-device, fully remote, or in a hybrid split design.
That is how you stay concrete without boxing the invention in too tightly.
Common drafting mistakes in AI patent specifications
It helps to be blunt here. Certain mistakes appear again and again.
One common mistake is describing the invention at the marketing level instead of the system level. The patent says the platform uses AI to personalize user experience, but it never explains how data is formed, how training occurs, or how runtime personalization is actually computed.
Another common mistake is naming the model but not the workflow. Saying “a neural network is used” adds very little by itself.
A third mistake is leaving out the data path. The draft says the model is trained, but not where examples come from, how they are labeled, or how they are cleaned.
A fourth mistake is making inference look trivial. The specification spends effort on offline training but ignores runtime constraints, routing, thresholds, and post-processing.
A fifth mistake is failing to explain the technical improvement. The system may be clever, but the draft never clearly states what changes operationally because of it.
Another mistake is overusing generic legal filler. The document becomes full of stock language and short on actual engineering content.
And finally, many teams file too late, after the system has changed and important early design choices have been forgotten. Good AI patent drafting is much easier when it captures the logic while the creators still remember why the pipeline was built the way it was.
A practical way to gather invention details from AI teams
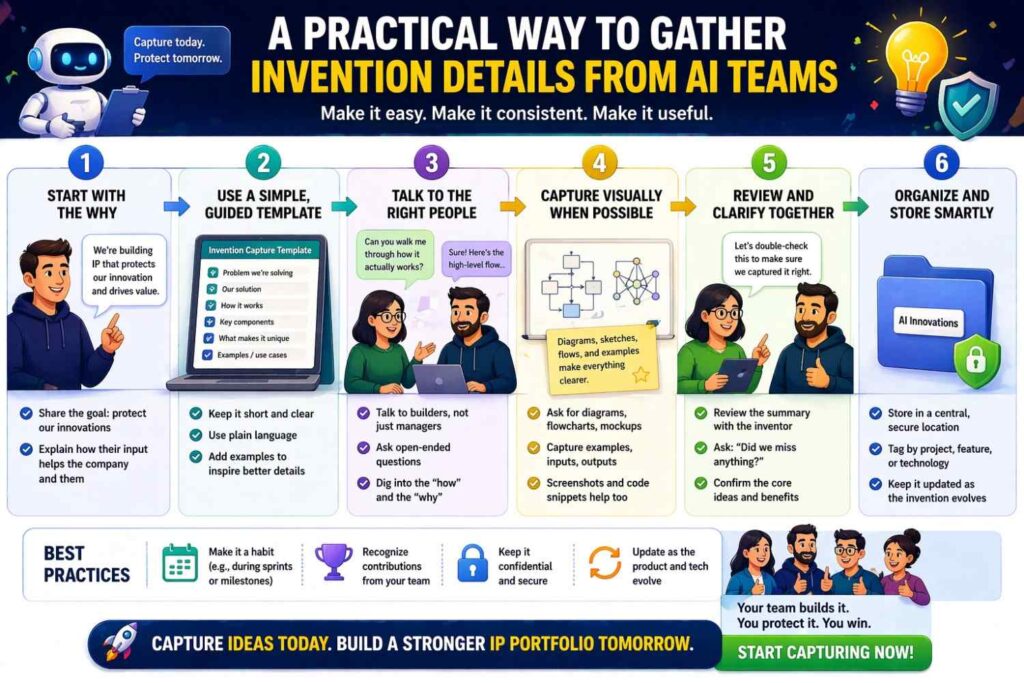
If you are preparing a patent specification for an AI invention, one of the best things you can do is ask the right practical questions early. Do not begin by asking only, “What model are you using?” That is rarely enough.
Ask what problem the team was trying to solve and why older methods failed. Ask what the inputs are and where they come from. Ask how raw records become training examples. Ask how labels are formed. Ask what the model learns to predict or generate.
Ask what preprocessing happens before training and what happens again at runtime. Ask whether the runtime system uses one model or many. Ask how confidence is handled. Ask what output is actually acted on. Ask whether live feedback returns to the training loop. Ask what measurable result improved after the new approach was introduced.
When you ask these questions, the patent usually becomes much richer. Often the most patentable material comes out in the answers to “how are examples built?” or “what happens when the model is uncertain?” rather than in the answer to “what model is it?”
Writing the specification in plain language improves patent quality
This point is worth stressing. Plain language is not a downgrade. It is a drafting advantage.
Complex words can hide weak thinking. Simple words force precision. If you say, in simple language, that the system groups events from a thirty-minute period, joins them to a later-confirmed failure record, and uses that pair as a training example, everyone understands what happened. That is strong drafting.
If instead you say the system employs temporally associated event aggregation for downstream predictive model optimization, it may sound advanced but say less.
Formal tone is still important, of course. A patent should not read casually. But formal does not mean stiff. A specification can be direct, readable, and exact at the same time.
The best AI patents often read like clear engineering documents with legal discipline, not like buzzword-heavy whitepapers.
How much implementation detail should you include
There is no perfect universal line, but there is a useful principle: include the details that explain the mechanism and the variations that preserve scope.
You usually do not need to paste code. You usually do not need exact dataset sizes unless they matter. You usually do not need every tuning parameter. But you should include enough structure so that the invention feels buildable and distinct.
For a training section, that may mean describing the example formation, labels, objective, and one or more model classes. For inference, that may mean describing the runtime input path, model selection or routing, thresholds, and output handling. For data, that may mean describing sources, transformations, joins, windows, and privacy constraints.
If a certain value or rule is critical, include it, at least as an example. If there are alternative values or methods, include those too.
The goal is not maximum volume for its own sake. The goal is useful technical depth.
AI patents should not oversell magic
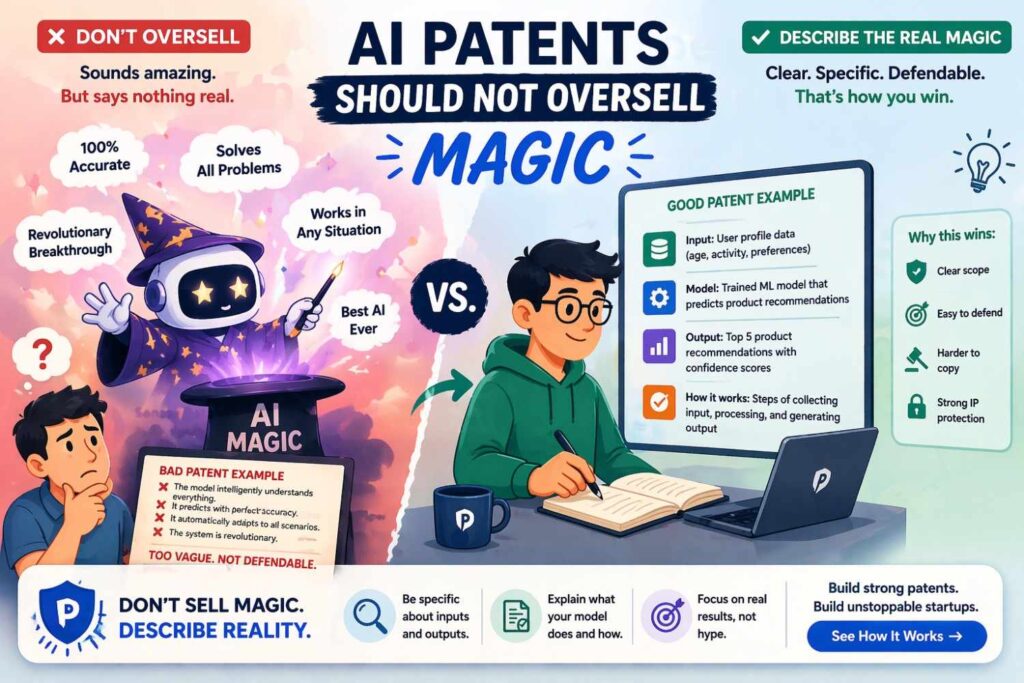
There is a temptation in some drafting to make the system sound almost limitless. It can predict anything, adapt to anything, improve everything. That style may feel exciting, but it often hurts the patent.
Examiners are skeptical of claims that sound like results without a disclosed path. Judges and opposing counsel are skeptical too. Broad promises with weak support can backfire.
A stronger approach is more disciplined. Explain exactly what the system does in one or more contexts. Explain the mechanics. Explain variants. Explain the technical gain. Let the depth of the disclosure create the breadth, rather than trying to grab breadth through inflated language.
This is especially true in AI because so many filings now use similar buzzwords. The patent that stands out is often the one that actually explains the engineering.
If the invention uses off-the-shelf models, can it still be patentable
Yes, sometimes. But the invention is usually not the mere use of the off-the-shelf model. The patentable value may be in how the model is adapted, what data it is trained or fine-tuned on, how inputs are structured, how outputs are constrained, how retrieval is performed, how runtime routing is done, or how the overall system achieves a technical effect.
For example, using a general language model may not be enough by itself. But building a domain-specific pipeline that transforms equipment logs into structured prompts, retrieves context-specific maintenance records, grounds generated recommendations in verified reference passages, and routes uncertain outputs to a review workflow may present much stronger patent material.
The key is to identify the system-level technical design around the model.
This is good news for many AI companies because their value often does sit in orchestration, data formation, workflow logic, and deployment, not only in building a model from scratch.
Industry-specific examples make the patent stronger

Even if you want broad coverage, giving industry-grounded examples can help. This does not necessarily narrow the invention if the draft is written well. It makes the system easier to understand.
In healthcare, you might explain how patient history, scan data, and lab values are combined. In manufacturing, you might explain how telemetry, maintenance notes, and control settings interact. In fintech, you might explain transaction flows, device state, and account behavior. In legal tech, you might explain clause extraction, retrieval, and ranking. In support automation, you might explain ticket text, prior resolutions, and user environment data.
These examples create life inside the specification. They also give later claim drafters more support for different angles.
The role of diagrams and flowcharts
Although this article is focused on the written specification, visuals can greatly help in AI patents. A training pipeline diagram, an inference flow, a system architecture figure, or a data preparation flowchart can support understanding and drafting consistency.
A figure may show raw data sources entering a preprocessing module, then a training example generation stage, then model training, then runtime inference, then a feedback collection stage. Another figure may show routing among local and remote models. Another may show multimodal fusion. Another may show retrieval and grounded generation.
These visuals should match the written description, not replace it. But when used well, they can help make the invention clearer and more complete.
Write for the future examiner and for the future business
A patent specification has two audiences across time. One is the examiner who will review it. The other is the business that may rely on it years later.
The examiner needs clarity, support, and a visible technical mechanism. The business needs a document that still maps onto product value even after model versions, vendors, and deployment patterns change.
That is why AI patents should focus on enduring workflow logic, data handling insights, runtime orchestration, and measurable technical effects. These are often the most stable parts of the moat.
If a specification is too tied to one current model name or one temporary implementation choice, it may age quickly. If it is too vague, it may never be strong. The middle ground is concrete system disclosure with thoughtful variation.
A sample structure for an AI patent specification
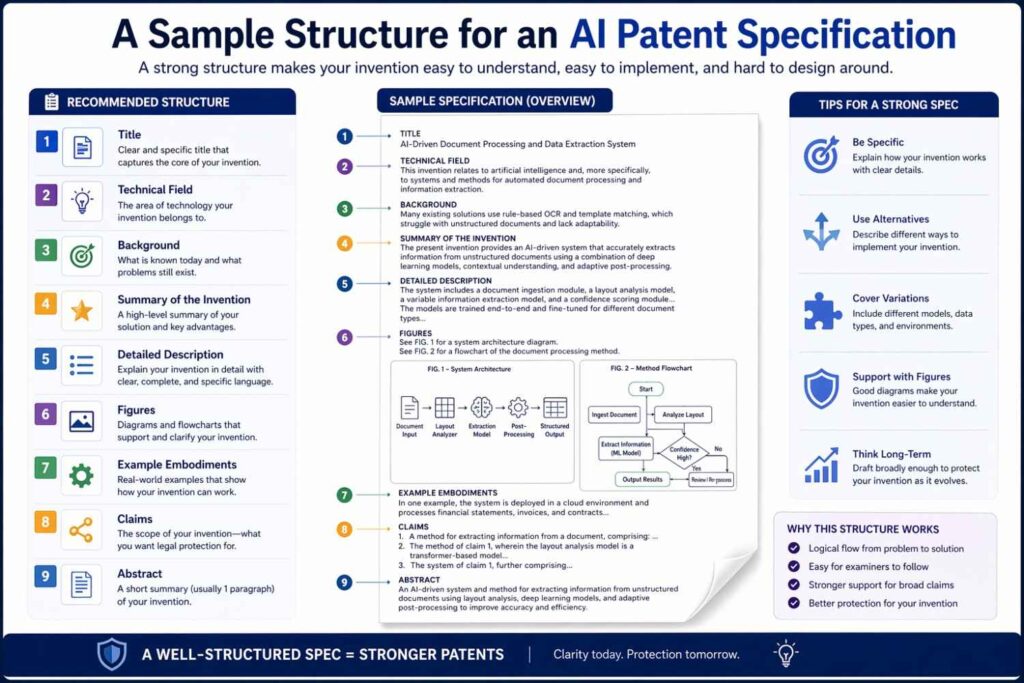
It can help to think about what a full draft might cover, even if the exact sections differ by jurisdiction or style.
The opening should frame the technical field and the practical problem. The background should describe limitations in existing approaches carefully. The summary should present the invention at a useful level, not just in slogans.
The detailed description should then walk through the system architecture, the data sources and preprocessing, the training example formation, the training process, the runtime inference path, model routing or thresholding if present, post-processing, feedback loops, deployment environment, and concrete examples.
Throughout the draft, the language should explain what each stage does and how the stages connect. Alternate implementations should appear naturally, not as an afterthought. The technical effect should be stated clearly.
You do not need to force lists everywhere. In fact, too many lists can make the document dry. Narrative explanation often works better, especially when you are trying to explain how the pipeline behaves.
The most powerful question when reviewing a draft
After a first draft of an AI patent specification is complete, ask one question:
Could a technically trained reader understand how training data is formed, how the model is trained at a useful level, how inference runs in practice, and why the system works better than prior approaches?
If the answer is no, the specification likely needs more depth.
A second useful question follows close behind:
Could future claims be written around training, data preparation, inference flow, feedback, and system architecture without inventing support that is not already in the draft?
If the answer is no, the draft is leaving value on the table.
A note on patents for AI tools versus AI-enabled products
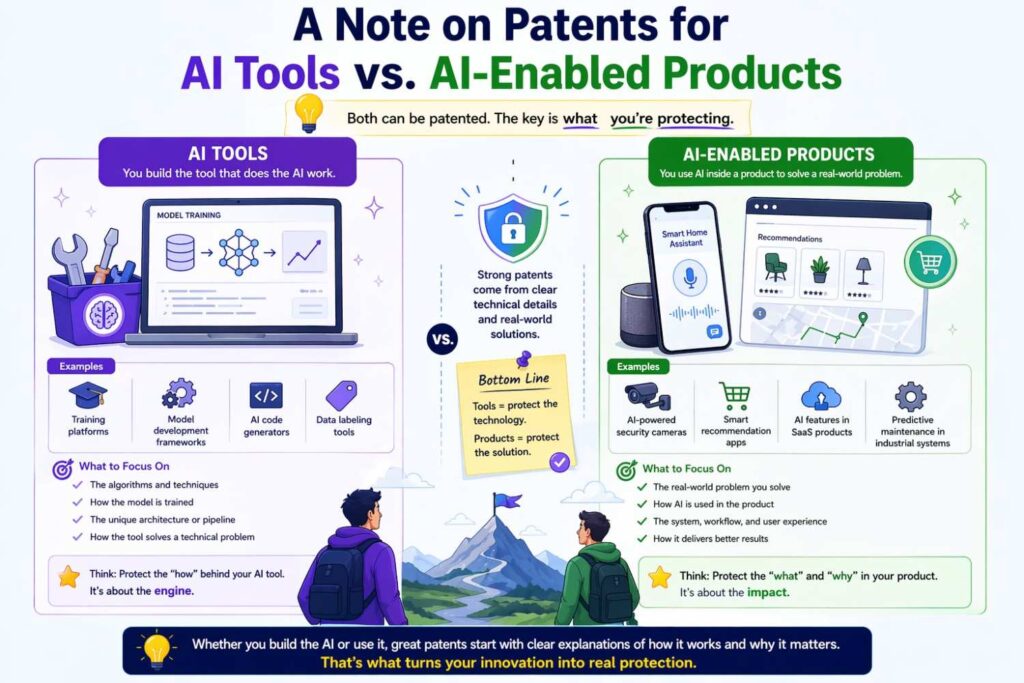
Some inventions are about the AI system itself. Others are about a larger product or process that uses AI as a key part. The drafting approach should reflect that difference.
If the invention is an AI tool, the specification may focus heavily on model training, evaluation, routing, and deployment. If the invention is an AI-enabled product, the specification should still explain the AI mechanics, but also show how the AI interacts with the broader system.
For example, a logistics platform may use AI to predict delays, but the real invention may be how those predictions are turned into dynamic routing actions and user notifications.
A medical system may use AI to flag scans, but the key may be how those flags restructure review order and reduce delay for urgent cases. A support product may use a language model, but the real value may be how verified knowledge retrieval and workflow state are combined to produce reliable action suggestions.
This distinction matters because a patent should protect where the business value actually sits.
Why early disclosure capture is so important for AI teams
AI teams change things fast. Prompts change. architectures change. data sources change. evaluation methods change. product goals shift. Because of this pace, waiting too long to prepare a patent draft can cause real loss.
Important details vanish from memory. Early trade-offs are forgotten. Prototype pipelines that revealed the inventive step are replaced by cleaner production versions. What looked obvious later was often hard-won at the time, but no one documents that struggle unless someone asks early.
This is why invention harvesting for AI should happen regularly. Teams should capture not only launches but also technical breakthroughs in data formation, model training methods, inference routing, human-in-the-loop design, and reliability controls.
A strong patent often begins with a good technical interview at the right moment.
What makes an AI specification commercially useful
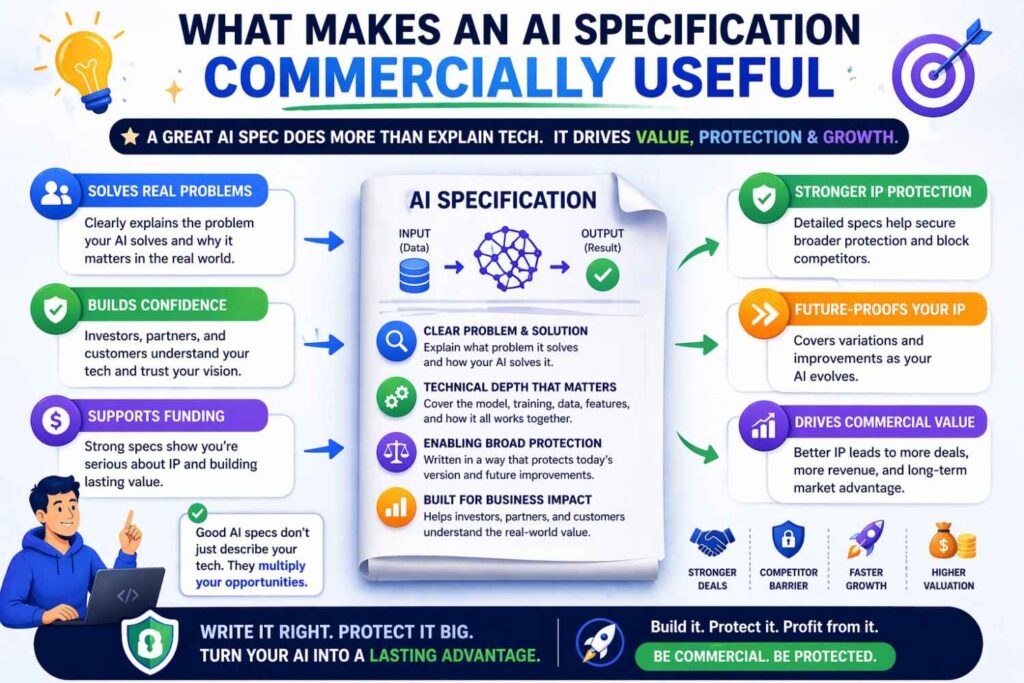
A commercially useful AI patent is not just one that gets granted. It is one that maps to how competitors are likely to build similar systems.
That usually means the specification should not focus only on one narrow implementation detail. It should capture the architecture, the data path, the training logic, the inference behavior, and the practical control points that others would need to use to achieve similar results.
For example, if competitors will likely use different model backbones but similar retrieval plus grounding plus confidence gating, then the specification should emphasize those layers.
If competitors may use different classifiers but must still form labels from delayed events and route uncertain cases to humans, those features deserve strong support. If the moat lies in privacy-preserving local feature extraction and selective cloud escalation, that should be central.
Commercial usefulness comes from drafting around the real operating design, not just around what sounds novel in a demo.
A commercially useful AI specification does more than support a filing. It helps protect the part of the business that actually creates leverage in the market. That is the standard businesses should use.
A lot of AI patent drafts look technically respectable, yet they do very little for the company once the filing is made. They may describe the system in a clean way, but they do not cover the pressure points that matter in a live business setting. They do not track how revenue is created.
They do not map to where product stickiness comes from. They do not reflect how a competitor would realistically rebuild the same result. And they often miss the internal workflows that make the solution hard to copy at scale.
A commercially useful specification fixes that problem. It is written with a clear view of where value is created, where substitution is likely, where competitors will try to enter, and where the company needs legal support if the product succeeds.
That changes the way the invention should be described.
It should protect the revenue engine, not just the technical engine
Many AI companies make the mistake of protecting the model while leaving the revenue mechanism exposed.
In practice, customers do not pay simply because a model exists. They pay because the system solves a business problem in a reliable, repeatable, and scalable way. That may include how outputs are delivered into a workflow, how decisions are prioritized, how latency is controlled, how trust is created, how errors are reduced, how compliance is managed, or how the product becomes embedded into day-to-day operations.
A commercially useful specification should therefore ask a harder question than “what is technically interesting here?”
It should ask, “what part of this system would a competitor need to imitate in order to compete with us in a serious way?”
That answer often sits in the full operating flow. It may be the handoff between AI output and human action. It may be the gating logic that turns model predictions into safe automation. It may be the layered workflow that moves a user from insight to decision to action. It may be the way the system plugs into customer data and keeps improving over time.
When those elements are described properly, the specification becomes tied to business value instead of technical decoration.
The best specifications are built around replacement risk
One of the smartest ways to judge commercial usefulness is to think in terms of replacement risk.
Imagine a competitor wants to replace your product inside a customer account. What would they have to rebuild? Not what would they market. What would they actually have to engineer?
Would they need to recreate your data intake pipeline? Your event labeling method? Your confidence-based review workflow? Your customer-specific adaptation layer? Your runtime routing logic? Your retrieval and validation system? Your audit trail? Your integration between AI output and enterprise action?
Those are the parts that often deserve heavy attention in the specification.
This way of thinking is helpful because it forces the patent effort to move away from surface-level novelty. It focuses the draft on what cannot be casually swapped out.
For businesses, this is an extremely practical exercise. The patent team should sit with product and engineering and ask, in plain language, “If someone copied the business outcome, what are the technical pieces they would almost certainly need?” The answer to that question is usually more valuable than a long discussion about whether the model is called one thing or another.
Protect the adoption layer, not only the invention layer
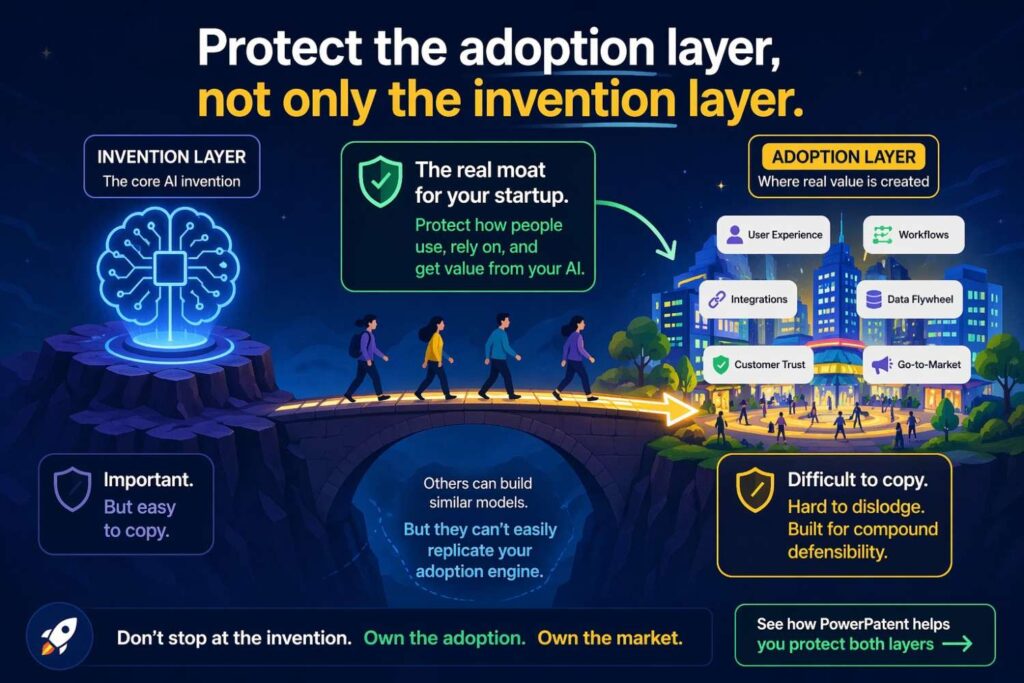
A great AI product can still fail commercially if users do not trust it, understand it, or fit it into their workflow. That is why the adoption layer matters so much.
In many businesses, the most defensible part of the AI system is not only the prediction or generation step. It is the design that makes the system usable inside a real operating environment. That can include confidence displays, ranked outputs, exception queues, explainability signals, human override tools, escalation logic, workflow triggers, and feedback capture.
These features are sometimes treated as secondary. They should not be.
If those elements are part of what makes the product stick inside a customer organization, the specification should describe them carefully. In many enterprise deals, buyers do not adopt AI because it is clever. They adopt it because it fits risk controls, reduces friction, and creates a repeatable path to action.
A commercially useful patent specification can support this by treating trust and operational usability as technical features of the system, not as product polish.
Strong specifications cover the path from output to action
A common weakness in AI patent drafting is that the document stops too early. It explains how the model produces an output, but not how the output creates value for the user or customer.
Commercial usefulness grows when the specification explains what happens after the model responds.
Does the output trigger a workflow? Does it create a ranked queue? Does it fill fields in a downstream system? Does it generate a recommendation that is checked against live policy rules? Does it create a control signal? Does it open a review path for uncertain cases? Does it create a draft that is later approved by a person? Does it combine with system state before any action occurs?
These steps matter because businesses win when insight becomes execution.
A competitor may be able to create a similar prediction score. That alone may not threaten the business. The real risk appears when they can also recreate the exact way that score moves through a customer workflow and turns into time savings, lower error rates, better decisions, or higher conversion.
That is why businesses should push for a specification that follows the full path from AI output to operational result.
Commercial usefulness depends on claim flexibility later
Businesses often do not know at filing stage where market pressure will come from in two or three years. Competitors may copy the training method, or the runtime flow, or the integration layer, or the customer feedback loop. The patent specification needs to prepare for that uncertainty.
This is where commercial usefulness becomes tightly linked to optionality.
A strong specification gives future claim drafters room to move. It creates support for claims around different layers of the system so the company is not forced into one narrow theory later. This matters because litigation, licensing, and competitive response do not happen under ideal conditions. They happen under pressure.
If the specification supports only one angle, the business may have a patent that looks good in a report but is difficult to use strategically. If the specification supports several paths, the company can align its patent position with what the market actually does later.
For businesses, this means one practical thing: when preparing the draft, do not ask for one story only. Ask for the primary invention story and at least two secondary technical stories that also deserve support. That discipline often leads to much stronger filings.
A useful specification matches the way customers buy
This point is often missed, but it matters a lot. Customers do not buy AI products in the abstract. They buy outcomes through a package of technical and operational features.
Some customers buy speed. Some buy accuracy. Some buy auditability. Some buy workflow automation. Some buy lower staffing load. Some buy better detection of edge cases. Some buy privacy controls. Some buy reliability under messy real-world inputs.
A commercially useful specification should reflect the factors that actually drive customer adoption and renewal.
If customers consistently choose the product because it reduces review time by routing only uncertain cases to people, that logic should not be an afterthought in the patent. If customers value the system because it works inside strict privacy settings through local inference or selective transmission, that should be central. If the product wins because it can produce grounded outputs tied to internal records, that mechanism should be described deeply.
This is strategic because it connects patent drafting to the sales reality of the company. A patent becomes more useful when it protects what customers truly pay for.
The specification should account for enterprise friction
Commercial value is often created by solving friction that looks boring from the outside but is very hard to remove in practice.
For example, an AI product may become successful not because the core model is radically different, but because it handles poor data quality, partial records, changing user behavior, strict approval requirements, unstable connectivity, or difficult legacy systems better than others.
These kinds of features deserve serious treatment in the specification if they are part of the product’s business advantage.
That is because enterprise value is frequently hidden in reliability. A product that works only under ideal conditions is easy to demo and hard to scale. A product that works inside messy customer environments becomes much harder to replace.
A commercially useful patent should capture the mechanics that make the system durable under those messy conditions. That can include fallback paths, missing-data logic, policy gating, local caching, asynchronous execution, model escalation, review loops, system reconciliation, or deployment-specific tuning.
From a business perspective, this is a major opportunity. Many companies overlook these details because they do not sound glamorous. In truth, they are often the most monetizable parts of the product.
Write for competitor behavior, not just examiner review

Most patent drafts are written as if the only audience is the examiner. That is too narrow.
A commercially useful specification should also be written with competitor behavior in mind. You are not only trying to get a patent allowed. You are trying to describe the invention in a way that reaches the methods rivals are likely to adopt once the market proves there is money to be made.
This means the drafting process should include a practical exercise. The business should identify how likely competitors will build a similar solution if they are trying to move fast.
Will they use open models with proprietary routing? Will they rely on customer data integration? Will they create a retrieval layer to improve output quality? Will they use human review on only the highest-risk cases? Will they segment customers by deployment type? Will they tune models per industry?
These likely copy paths should influence the specification.
This is highly actionable advice for businesses: before finalizing the invention write-up, create a short internal memo titled “How a fast follower would copy this.” Then compare that memo against the draft. If the draft does not meaningfully cover those copy paths, the filing may not be commercially aligned yet.
The most useful patents often cover scaling mechanics
What makes an AI company valuable is not always the first version of the product. It is often the ability to scale the product across customers, data environments, languages, device types, industries, and compliance settings.
That is why scaling mechanics can be very important in a commercially useful specification.
Maybe the system supports customer-specific adaptation without full retraining. Maybe it handles different data schemas through normalization layers. Maybe it routes tasks based on deployment environment.
Maybe it allows model reuse across customers while preserving local privacy controls. Maybe it supports incremental improvement as new feedback arrives. Maybe it builds domain-specific knowledge structures that keep output quality high across sectors.
If those are part of the real commercial engine, they should be written into the specification.
Businesses should be careful here. Many teams focus patent effort on the first narrow technical breakthrough but ignore the features that made the business scale beyond one account. In the long run, those scaling features may have more strategic value than the original demo.
Protect the hard-to-copy operating discipline
Some of the strongest AI businesses are not built on a single flashy model improvement. They are built on operating discipline that is hard to replicate.
That discipline might include how low-quality data is filtered before training, how customer feedback is converted into reliable supervision, how domain experts review only selected cases, how model updates are deployed safely, how outputs are checked before action, or how the system measures drift and intervenes before failure spreads.
These are business assets. They are not just process details.
A commercially useful specification can help preserve them by describing the technical workflows that make the discipline real. This is especially important for AI businesses that win through reliability, trust, and operational consistency rather than through a headline benchmark.
From a strategic view, this means companies should stop assuming the patent-worthy invention must be the most exciting part of the product. Sometimes the real moat is the disciplined method that keeps the product useful at customer scale.
Actionable advice: run a value-map session before drafting
One of the best practical steps a business can take is to run a short value-map session before the patent draft starts.
In that session, gather product, engineering, legal, and one commercial leader. Then answer four questions in simple language.
First, what part of the system makes customers pay?
Second, what part makes them renew?
Third, what part would a competitor most likely copy first?
Fourth, what part would be hardest for them to copy well?
The overlap between those answers is where commercial patent value often sits.
This advice is highly useful because it pulls the patent discussion out of a purely technical silo. It helps the draft reflect market reality. It also reduces the chance that the application will focus on a detail that feels inventive internally but matters very little commercially.
Actionable advice: capture the “must-have” workflow in one narrative
Another strong tactic is to force the internal team to describe the product as one full workflow, from input to value delivered.
Not a feature list. Not a model list. One end-to-end story.
For example, what enters the system, what is processed, what the AI does, what checks happen, what output is generated, what decision follows, and what business metric improves.
This exercise is powerful because it reveals the exact places where commercial value is created. Those points should then be reflected in the specification with enough detail to support future claims.
If the team cannot tell that workflow clearly, the patent draft will often end up too abstract. If they can tell it clearly, the drafting process becomes much stronger.
Actionable advice: include competitor-proof variants
When businesses think strategically, they realize competitors rarely copy a system exactly. They copy around it.
That means the specification should not only describe the company’s current implementation. It should also include variants that competitors would likely use to reach the same result.
If your current product uses one training method, include support for similar methods that solve the same technical issue. If your system uses one type of confidence gating, describe other gating approaches that could perform the same role. If you use one deployment model, include local, remote, and hybrid variants where appropriate.
This is not about guessing wildly. It is about protecting the commercial space around the core idea.
A useful internal prompt is this: “If we were our own competitor, what would we change to avoid direct copying while keeping the same customer value?” The answers should influence the specification.
Actionable advice: tie technical features to business metrics in the draft notes
Even if every commercial metric does not belong in the formal patent text, it is smart to capture them during invention intake.
For each major technical feature, ask what business result it supports. Faster turnaround. Lower review cost. Higher output trust. Reduced false alerts. Better user retention. Faster onboarding. More reliable performance in poor data settings. Lower compute expense. Better compliance fit.
This helps legal and drafting teams understand what to emphasize.
It also helps later when the company needs to decide which patents matter most. Patents tied to revenue, cost savings, or adoption drivers are easier to prioritize than patents tied only to technical curiosity.
Actionable advice: revisit the specification after product-market fit begins
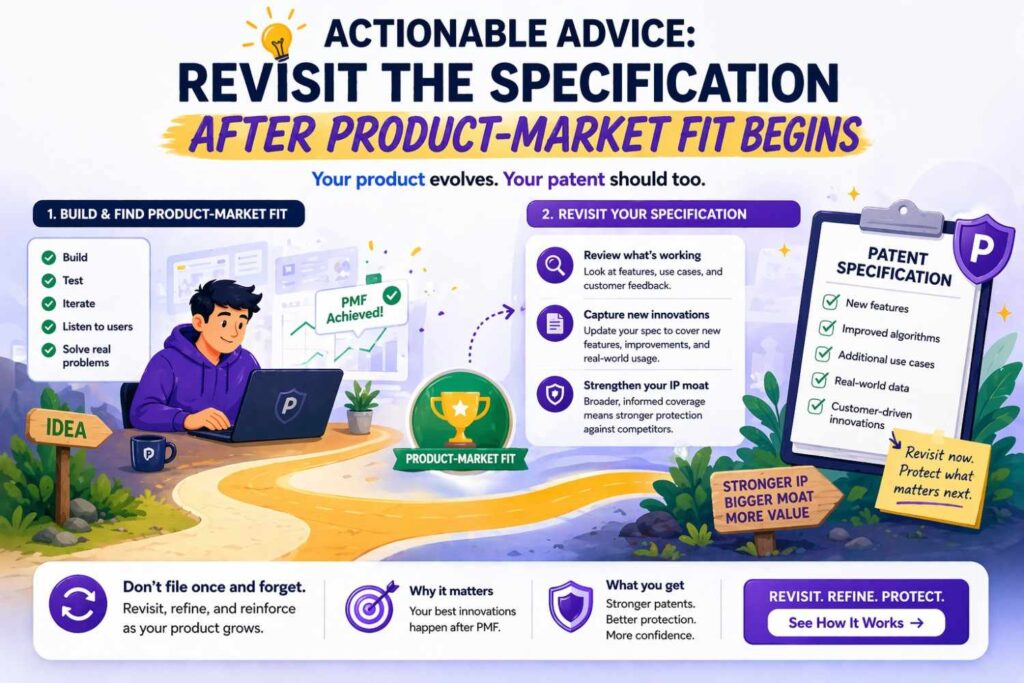
Many companies file early, which is often wise, but then never revisit the strategic framing of that invention. That is a missed opportunity.
Once product-market fit begins to appear, the company has better information about what customers value, what slows deals, what drives usage, and what competitors emphasize. That new commercial knowledge should inform continuation strategy, follow-on filings, and claim direction.
The first specification may already contain useful support if it was drafted well. But businesses should actively review it in light of market feedback. Ask whether the disclosed invention aligns with the parts of the product that now matter most commercially.
This is not just legal housekeeping. It is patent portfolio strategy.
Commercial usefulness comes from business clarity
In the end, what makes an AI specification commercially useful is not only technical depth. It is business clarity expressed through technical disclosure.
The specification should show where the company creates value, where competitors will try to follow, what customers truly depend on, and which system mechanics make the product hard to replace. It should protect more than a model. It should protect the operating logic that turns intelligence into business advantage.
That is the difference between a patent filing that looks impressive on paper and a patent asset that actually helps the company defend market position.
For businesses building in AI, that difference is everything.
Final thoughts: clear AI patent drafting wins
AI can make inventions feel complex. Patent drafting does not need to make them confusing.
The strongest patent specifications for AI are usually the ones that stay close to the real technical workflow. They explain the data. They explain the training. They explain the runtime behavior. They explain what happens when the system is uncertain. They explain how outputs become useful actions. They explain why the result is better in a real environment.
They do not hide behind empty phrases. They do not assume the reader knows the pipeline already. They do not treat training, inference, and data as boxes to check. They treat them as the core of the invention.
If you are drafting or reviewing a patent specification for AI, focus on the mechanism. Ask how training examples are formed. Ask what the model learns. Ask what happens during inference under real constraints. Ask how data moves through the system. Ask what practical technical effect follows from the design.
When those answers are in the specification, the patent has a much better chance of becoming something useful.
And that is the real point.
Not just to say your company uses AI.
But to explain, clearly and completely, what your system actually does that others do not.