Most AI patents sound smart but say very little.
That is the problem.
You can build a strong model. You can train it on clean data. You can ship a product people love. But if your patent does not clearly explain what goes into the model and what comes out of it, you leave a hole right in the middle of your invention.
That hole can cost you.
If you are building AI, machine learning, or software that makes decisions from data, you need to explain your model in a way that is clear, broad, and useful. Not vague. Not stuffed with buzzwords. Not trapped in research paper language. You need language that helps protect the real value of what you built.
That is exactly where many founders get stuck.
This guide will show you how to describe model inputs and outputs in a patent in a way that is simple, practical, and much more likely to support a strong filing. And if you want help turning your product, code, or model into a real patent strategy without slowing your team down, see how PowerPatent works here: https://powerpatent.com/how-it-works
Why this part of the patent matters so much
When people think about AI patents, they often focus on the model itself. They think the magic is in the neural network, the architecture, the training loop, the loss function, or the fine-tuning method.
Sometimes that matters.
But in many real products, the real value is not just inside the model. The value is in the full system. It is in what data the model receives, how that data is prepared, how the model uses it, and what result the model produces so the rest of the product can act on it.
That means the inputs and outputs are not side details. They are often the backbone of the invention.
A patent examiner, investor, future buyer, or even a competitor reading your patent needs to understand what your system receives and what your system generates. If that story is fuzzy, the invention can look generic. It can sound like “use AI on data to get a result.” That is not enough.
Clear input and output language helps do several important things at once.
First, it makes the invention concrete. It shows that your system is not just a wish. It is a real technical workflow.
Second, it helps show what is new. Many teams use models. Far fewer use a model with your specific input structure, your signal mix, your feature flow, and your output behavior.
Third, it helps support broader claims. This sounds backward at first, but strong patents often come from specific disclosure. When you explain enough detail, you create room to claim the invention in ways that are broad but still grounded.
Fourth, it helps avoid a very common mistake. A lot of founders describe the model in a way that is so narrow it only covers one current version of the product. Or they describe it so broadly that it sounds empty. You want the middle path: real enough to hold up, flexible enough to grow with the company.
That is one of the biggest reasons founders use PowerPatent. The platform helps you capture the real technical story behind your system, with software built for speed and clarity, backed by real patent attorneys who know how to turn product details into strong filings. You can see the process here: https://powerpatent.com/how-it-works
What “inputs” and “outputs” really mean in a patent
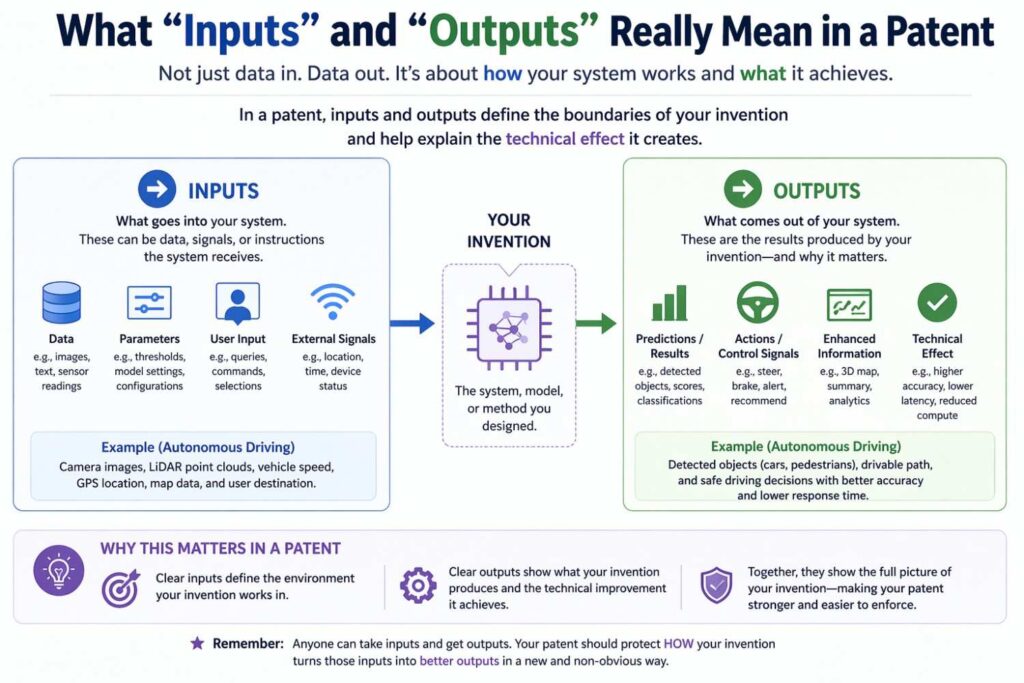
In plain words, an input is whatever the model receives and uses to produce a result.
An output is whatever the model produces that can be used by another part of the system, shown to a user, stored in memory, sent to another service, or used to control a next step.
That sounds simple. But in patent drafting, these ideas are broader than many people think.
An input is not only raw user data.
It can be a sensor stream, a set of derived features, a prompt, a message, a file, a history window, a graph structure, a prior prediction, a confidence score from another model, a user setting, a threshold, a ranking signal, a learned embedding, metadata, or a mix of all of these.
An output is not only a final label.
It can be a class score, a ranking, a generated text sequence, an image mask, an anomaly flag, a route, a recommendation, a control signal, a transformed representation, a compressed vector, a risk score, a set of actions, or even a decision about whether another model should run.
This matters because many founders describe the wrong layer.
They say the model takes in “data” and produces “a result.” But that tells the reader almost nothing.
The better question is this: what exactly enters the model at the moment the invention becomes technically meaningful, and what exactly leaves the model in a way that changes what the system can do?
That is what you want to describe.
In a patent, inputs and outputs are not just nouns. They are part of a system story.
The model may receive a first set of data from a user device, a second set of data from a sensor array, and a third set of context values from a stored profile. A preprocessing module may normalize the data, align timestamps, remove missing values, create features, and generate a feature vector. The model may then output a predicted event value and a confidence value. A downstream action engine may use those outputs to trigger a recommendation or automate a control step.
That kind of chain helps show technical structure. It helps the reader see the invention as a working machine, not a vague idea.
The biggest mistake founders make
The biggest mistake is writing the patent like a product page.
A product page says things like this:
“Our AI analyzes user behavior and provides personalized recommendations.”
That may be fine for marketing. It is weak for patent drafting.
Why? Because almost any AI company can say that.
The phrase does not tell the reader what user behavior means. It does not tell the reader what parts of the behavior are used. It does not tell the reader how those inputs are represented, grouped, timed, weighted, transformed, or selected. It does not tell the reader what the recommendation output really is or how it affects the system.
A better patent description might say that the system receives session-level interaction events including click timing, dwell length, navigation order, and prior conversion events; generates a sequence representation for a current session; combines that representation with a user preference embedding and item metadata vectors; applies a trained model to estimate a predicted interaction value for each candidate item; and outputs a ranked subset of items with associated confidence values for display in a user interface.
Now the invention starts to sound real.
The best patent language does not just say the model helps the product. It shows how the system operates in a way that can be understood, defended, and claimed.
Another common mistake is to describe only one exact implementation. Founders often do this because they are close to the code. They say the input is a 384-dimensional vector made from three exact sources, fed into one exact transformer model, which outputs one exact scalar.
That may be true today. But what happens six months later when the team changes the encoder, adds a new context stream, or produces multiple outputs instead of one?
If the patent only describes the current version in one narrow way, it may fail to cover the next version of the product.
You need enough detail to show substance, but enough flexibility to cover reasonable variants.
That balance is hard to do well without help. That is why teams use PowerPatent to capture the invention while it is still fresh, then shape it into a filing that protects more than a snapshot of this week’s code. Learn more here: https://powerpatent.com/how-it-works
Start with the problem the model solves
Before you write a single sentence about inputs or outputs, step back.
Ask one simple question: what real system problem does the model solve?
Not “what model did we train?”
Not “what paper inspired it?”
Not “what benchmark did we beat?”
Ask: what problem inside the product needed this model?
Maybe the model predicts machine failure from noisy telemetry. Maybe it detects abuse in real time. Maybe it generates structured fields from messy documents. Maybe it matches users to tasks. Maybe it ranks messages. Maybe it estimates demand. Maybe it identifies code changes likely to break production. Maybe it interprets medical signals. Maybe it helps autonomous hardware act more safely.
This matters because the input and output language should connect directly to the problem.
If the problem is fraud detection, the meaningful inputs may include event timing, merchant identity, device signatures, account history, and cross-session behavior. The output may be a fraud likelihood score, a block action, or a review routing decision.
If the problem is document extraction, the inputs may include image regions, token locations, text strings, layout metadata, and document type signals. The outputs may include extracted fields, confidence values, and links between values and source regions.
If the problem is workflow automation, the inputs may include prior task states, message text, user roles, project context, and deadline data. The outputs may include a next-action proposal, a priority score, and a suggested assignee.
When you define the problem first, you avoid generic language. You also make it much easier to explain why the chosen inputs matter and why the outputs are useful.
A good patent does not read like a random bag of technical details. It reads like a thoughtful answer to a real technical challenge.
Describe the input at the right level
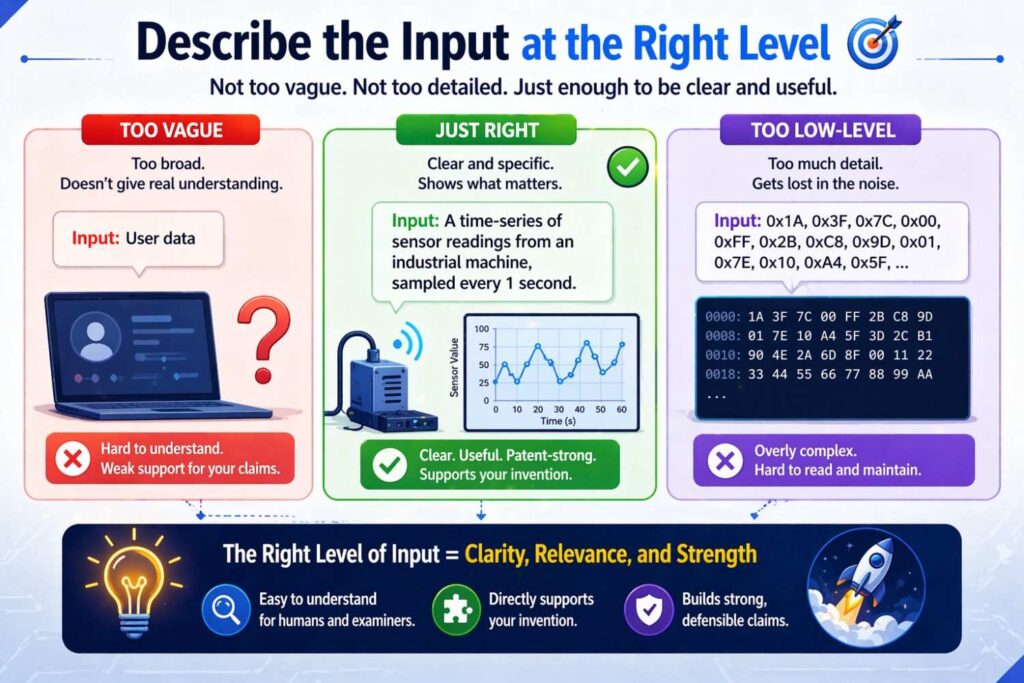
This is where many drafts go wrong.
Some describe the input too high up. They say “the model receives user data.” That is too vague.
Some describe the input too low down. They say “the input is a float32 tensor of shape [1, 128, 768].” That is often too narrow and not very helpful on its own.
The right level usually sits in the middle.
You want to say what kind of information is being received, where it comes from, what role it plays, and how it may be represented, without locking yourself into one exact implementation unless that exact form is part of the invention.
Think of input description in layers.
At the first layer, describe the source. Is the input from a user device, a database, a camera, a microphone, a wearable, a software log, a network event stream, a vehicle system, or another model?
At the second layer, describe the content. Is it text, image data, audio data, transaction records, time-series readings, document tokens, code segments, graph edges, geolocation signals, or prior behavior events?
At the third layer, describe the structure. Is it a sequence, a matrix, a feature vector, a graph, a set of windows, a prompt with fields, a batch of records, or a multimodal bundle?
At the fourth layer, describe optional processing before the model uses it. Is the input normalized, filtered, encoded, tokenized, embedded, segmented, aligned, sampled, compressed, or enriched with metadata?
At the fifth layer, describe why that input matters. Does it capture short-term behavior, historical context, environmental state, user intent, machine condition, or inter-object relationships?
You do not need to present these as a visible list in the patent. But you should think through them.
For example, instead of saying, “the model receives manufacturing data,” you can say that the system receives time-stamped sensor measurements from industrial equipment, including temperature values, vibration values, motor current values, and operating mode values; groups the measurements into rolling windows associated with a machine identifier; generates normalized feature sets for each window; and provides the feature sets as model inputs to predict a machine fault event.
That is much stronger.
It is simple. It is grounded. It sounds like a real system.
Raw inputs versus engineered inputs
One thing that confuses teams is whether the patent should describe raw data or processed features.
The answer is often both.
Raw inputs are the original signals or records your system receives. Engineered inputs are transformed versions of those signals that the model actually uses.
Sometimes the invention is in using raw input directly. For example, an end-to-end speech system may operate on raw or near-raw waveform segments.
Sometimes the invention is in feature construction. For example, your system may build a special sequence of derived signals from transaction behavior, or a graph representation from code dependencies, or a feature map from overlapping sensor windows.
If you only describe the raw data, you may miss the real technical value.
If you only describe the engineered features, you may fail to show where they came from and how the broader system works.
A better approach is to explain the chain.
You can say that the system receives raw records, then creates one or more processed representations that are provided to the model. That keeps the disclosure broad enough to cover different model types while also showing the specific technical flow that makes the invention useful.
Here is the core idea: do not act like preprocessing is boring. In many AI inventions, preprocessing is where the clever work lives.
Founders often downplay this because they think patents should focus on the “AI part.” But the truth is that how you prepare the input can be one of the most protectable parts of the invention.
Maybe you align multiple time streams in a special way. Maybe you generate a hybrid representation that mixes event history and static profile data. Maybe you compress long context into a learned memory. Maybe you create candidate sets before ranking. Maybe you generate patches or tiles from large images in a selective way.
Those details can matter a lot.
What makes an input description strong
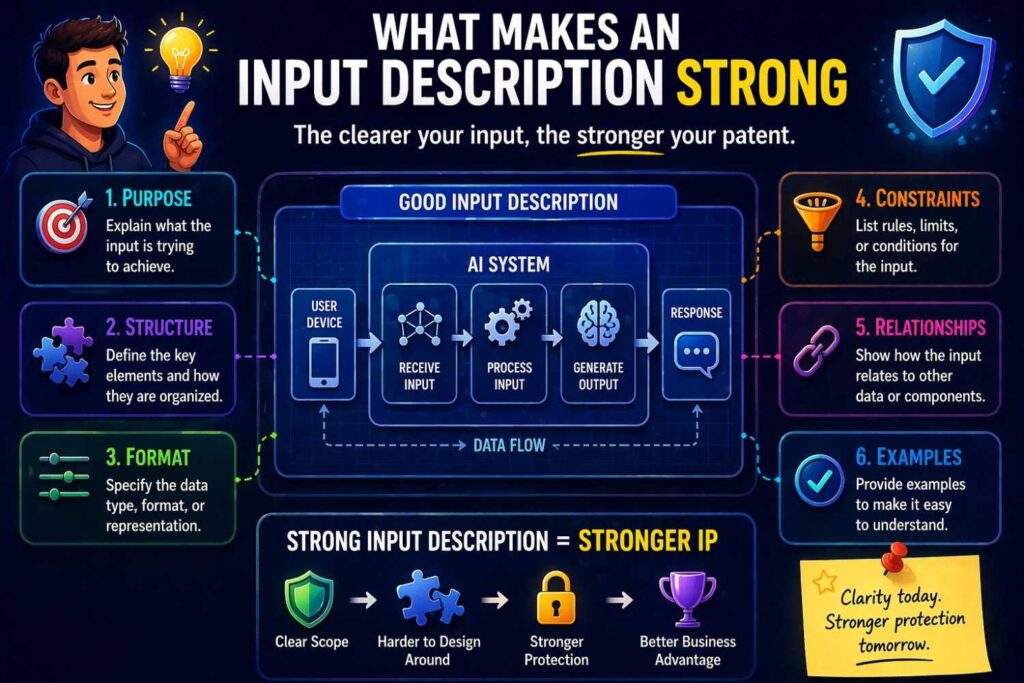
A strong input description usually has five qualities.
It is specific enough that a smart reader can picture what enters the system.
It is functional enough to show why that information matters.
It is broad enough to cover variants.
It fits inside the larger workflow.
It avoids empty buzzwords.
Take a weak sentence:
“The model receives contextual information and determines an output.”
This says almost nothing.
Now make it stronger:
“The system receives contextual information associated with a current user session, including a set of prior interaction events, a current page state, a device type, and one or more profile attributes, and provides the contextual information to a trained model configured to estimate a next-action likelihood.”
Now the reader knows what context means in this system.
You can improve it further by describing optional forms:
“In some implementations, the prior interaction events are represented as a time-ordered sequence. In some implementations, the profile attributes are represented as categorical values encoded as embeddings. In some implementations, the current page state includes content identifiers and interface element positions.”
That gives flexibility.
This is the move you want to make over and over. Replace vague category words with concrete but expandable descriptions.
Instead of “sensor data,” say “accelerometer measurements, gyroscope measurements, and location measurements.” Instead of “document data,” say “recognized text tokens, token coordinates, line groupings, and page image regions.” Instead of “system state,” say “resource usage values, queue depth values, service latency values, and recent error event counts.”
The goal is not to flood the reader with technical clutter. The goal is to say enough that the invention feels real.
Do not describe only data types. Describe meaning.
A patent is not just a schema file.
This is one of the most important points in the whole article.
Many technical founders default to what they know best. They describe inputs in code terms: integers, floats, arrays, strings, tensors, JSON objects.
Those details can help in some cases. But on their own, they are not enough.
Patents protect inventions, not just formats.
So you want to describe what the input means in the real system.
A timestamp is not just a number. It may indicate when a machine state change occurred relative to a prior fault.
A vector is not just a list of floats. It may represent semantic content, user preferences, a region of an image, a graph neighborhood, or a combined state across multiple devices.
A label is not just text. It may define an operating mode, a document class, a security rule, or a user-selected target.
When you describe the meaning of the input, you make the invention easier to understand and harder to dismiss as generic data processing.
You can still mention the technical form. In fact, you often should. But pair form with meaning.
For example, instead of saying, “the input includes a vector of values,” say, “the input includes a feature vector representing user navigation behavior within a defined session interval, the feature vector including values derived from page transitions, dwell duration, and prior action outcomes.”
That sentence does more work.
Explain relationships between inputs
Many useful AI systems do not rely on one input. They rely on multiple inputs that interact in a meaningful way.
This is where a lot of hidden patent value sits.
Maybe the model compares current state to prior state. Maybe it combines live sensor data with stored calibration data. Maybe it merges user text with knowledge base content. Maybe it uses image data and device position together. Maybe it ranks one candidate relative to a set of alternatives. Maybe it uses one model’s prediction as another model’s input.
When these relationships matter, say so.
The patent should not read like a grocery list of unrelated variables. It should show how the inputs fit together.
Examples of useful relationships include timing relationships, spatial relationships, identity relationships, source relationships, ranking relationships, and dependency relationships.
Suppose your system predicts shipping delays. The meaningful detail may not be just that the model receives route data and weather data. It may be that the model receives route segment data aligned to forecast windows and vehicle capacity states for the same delivery unit. That relationship can matter.
Suppose your system extracts fields from contracts. The meaningful detail may not be just that it receives text and layout. It may be that the model receives token data linked to line positions and section headings, so the model can distinguish similar terms based on document structure.
Suppose your system detects software incidents. The meaningful detail may not be just that it receives logs and metrics. It may be that the model receives temporally aligned service metrics and event log segments associated with a deployment interval.
These relationships help show technical thought. They also create hooks for broader and more defensible claims.
Sequence, time, and context deserve special care
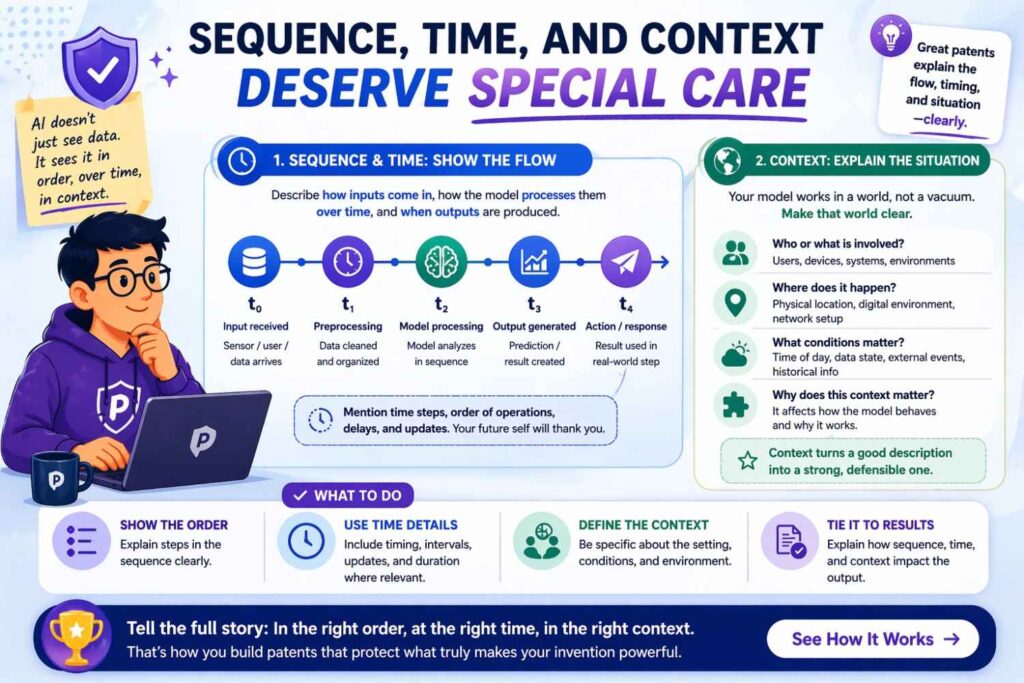
A huge number of modern AI products rely on time.
User sessions happen over time. Machine telemetry changes over time. Fraud often appears as a pattern over time. Language unfolds over time. Agent systems work across steps. Medical signals shift over time. Market activity changes over time.
If time matters in your invention, do not hide it.
Describe whether the model uses a point-in-time input, a history window, a rolling window, a sliding sequence, an event stream, or a state that carries over from earlier steps.
This can make a major difference.
A system that looks at one event in isolation is not the same as a system that interprets a sequence of events. A model that uses short-term context may behave very differently from one that uses long-term context. A system that updates outputs after each new event may be distinct from one that waits for a fixed batch.
If your invention uses temporal structure, explain the relevant timing behavior in simple words.
You might say the model receives a sequence of interaction events within a threshold time window before a target action. Or that the model receives telemetry values from a rolling interval and produces an updated health score each time a new sample arrives. Or that the system generates a context state from prior user messages and adds a new message representation before producing a response action.
These details do not need to be academic. They just need to be clear.
For multimodal systems, show how the pieces meet
Many newer products combine more than one kind of input.
Text plus image. Audio plus text. Sensor data plus maps. Logs plus code. Transactions plus graph relationships. User prompts plus retrieved knowledge. Camera frames plus motion signals.
If that is your system, do not simply say “the model receives multimodal input.”
That phrase sounds fashionable but thin.
Instead, explain what kinds of data are combined, what role each type plays, and how the system brings them together.
For example, a support automation system might receive message text, account activity data, and prior ticket resolution data. The text may help identify the issue type. The account activity may show what happened recently. The prior resolution data may guide likely next actions.
A robotics system might receive camera images, inertial readings, and map data. The image data may capture the current scene. The inertial readings may indicate movement state. The map data may provide route context.
A document intelligence system might receive page image regions and recognized text tokens. The image regions may preserve visual structure. The text tokens may preserve semantic content.
The point is not to sound advanced. The point is to make the technical role of each input understandable.
Then explain how the model or the surrounding pipeline uses the combined information. Is one input encoded first and then joined with another? Are separate models used before a fusion step? Does one input guide filtering of another? Does one input select which second input to retrieve?
Those connections can be very important in a patent.
Inputs can include prompts, rules, and constraints
Founders sometimes forget that a model input is not limited to data pulled from the world.
A model may also receive instructions, system constraints, user preferences, policy rules, thresholds, templates, or task definitions.
This is especially important in products built around foundation models, LLMs, or workflow agents.
For example, a system may receive a prompt that includes a task instruction, a set of retrieved records, one or more formatting rules, and one or more decision constraints. A model may then generate output that must satisfy those rules.
In another case, a ranking model may receive business constraints, such as inventory rules or safety exclusions, in addition to user relevance features.
In another case, a medical support model may receive both patient values and protocol definitions that shape interpretation.
If these non-data inputs matter to the invention, disclose them.
They often help show that the system is more than a plain call to a generic model.
This is one reason AI patents today need careful drafting. A lot of value now sits in system design around the model, not only inside the weights. Capturing that clearly can make a major difference.
Now let’s talk about outputs
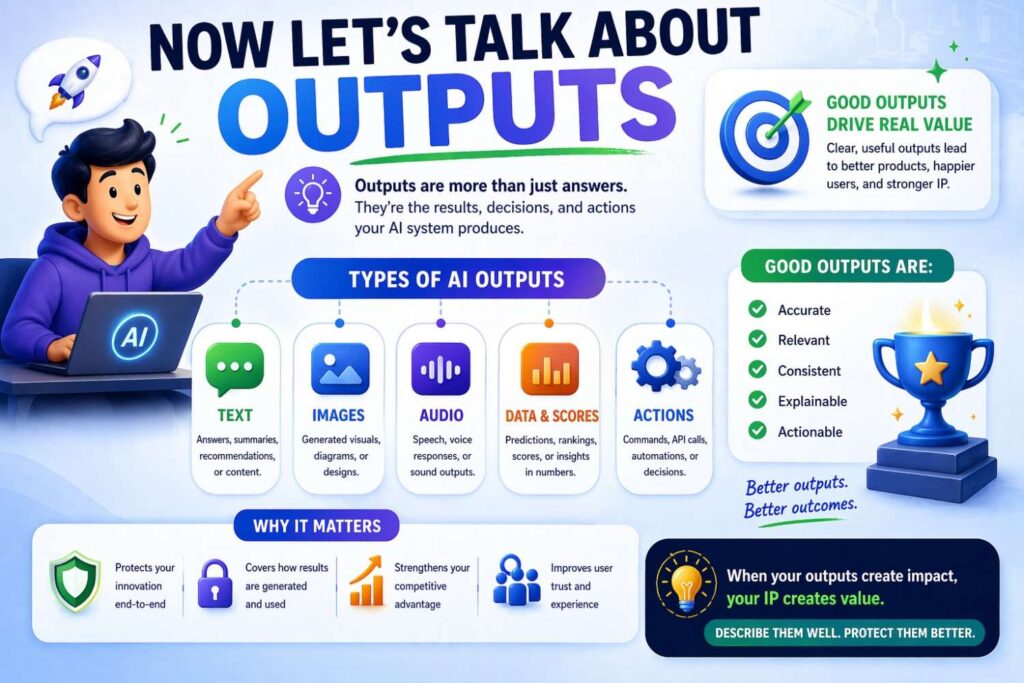
Most founders are weaker at describing outputs than inputs.
Why? Because teams often think of the output as “the answer.” They assume it is obvious.
But in patents, the output deserves the same care as the input.
Ask these questions.
What exactly does the model produce?
In what form?
At what point in the workflow?
For whom or for what module?
What happens next because of that output?
Those questions matter because a useful output is rarely just a final yes or no.
A model may produce one or more of the following: a probability, a score, a ranked list, a token sequence, a segmentation mask, a bounding region, an embedding, a state estimate, a proposed action, a route, an alert, a classification, a confidence value, a generated command, or a set of extracted values.
A strong patent description makes the output concrete and connected.
For example, instead of saying “the model generates a recommendation,” say that the model outputs a ranking of candidate content items with associated predicted engagement values, and that a display component selects one or more items from the ranking for presentation in a user interface.
Instead of saying “the model identifies a threat,” say that the model outputs a risk score for a network event and a classification label indicating a suspected threat type, and that a response module selectively blocks, flags, or routes the event based on the score and label.
Instead of saying “the model extracts information,” say that the model outputs a set of field values associated with document regions and confidence values, and that the field values are stored in a structured record.
This gives the invention shape.
Describe output meaning, not just format
Just like inputs, outputs should be described in both technical and functional terms.
Do not stop at “the model outputs a vector.”
What does the vector represent?
Maybe it represents a latent state for a device. Maybe it represents user intent. Maybe it represents semantic similarity. Maybe it represents a summary of the current conversation. Maybe it represents anomaly likelihood across multiple categories.
If the output is a score, explain what the score means. Is it likelihood of churn, urgency, quality, relevance, fault probability, confidence in extraction, or expected demand?
If the output is a label, explain the type of state or event it labels.
If the output is generated text, explain what the text is used for. Is it an answer draft, a command, a code patch, a summary, or a structured field response?
If the output is a control signal, explain what device or module receives it and what action it guides.
Meaning gives life to output language. It turns “a result” into a technical contribution.
The best output descriptions include downstream use

This is one of the easiest ways to strengthen a patent.
Do not describe the model output as if it appears and then floats in space.
Show what the system does with it.
Maybe the output changes a user interface. Maybe it triggers an alert. Maybe it updates memory. Maybe it selects a tool. Maybe it routes a record to another service. Maybe it changes a machine setting. Maybe it stores a representation for later matching. Maybe it determines whether a human review is needed.
This matters for two reasons.
First, it makes the invention more concrete. A system that produces a number and uses the number to control a next step sounds more technical and useful than a system that just produces a number.
Second, it helps with claim drafting. Outputs tied to downstream system action often create stronger claim language than bare predictions alone.
For instance, instead of just saying the model outputs a fraud score, say the fraud score is used to determine whether to approve, deny, or hold a transaction for review. Instead of just saying the model outputs a summary, say the summary is inserted into a task record or shown in a draft response interface. Instead of just saying the model outputs a route, say the route is supplied to a navigation controller that guides motion of a device.
This is one of the simplest upgrades you can make.
Think in output layers too
Just like inputs, outputs often come in layers.
There may be a raw model output, a processed output, and a system action output.
For example, the model may first generate probabilities over several classes. A post-processing module may convert those probabilities into a selected class and confidence. A business rule layer may then determine a routing decision. A user interface layer may then display a specific message.
If your invention includes those layers, explain them.
This helps in at least three ways.
It shows that the invention is a full system, not just a black-box model.
It creates room for claims at different levels.
It helps cover variants, because the final user-facing output may change over time while the model-level output and the decision flow stay similar.
This is especially useful in products built on fast-moving AI stacks. Your underlying model may evolve. Your prompt may change. Your user interface may change. But the core idea of how model outputs are converted into useful system actions may stay stable for a long time.
That stable layer is often what you want the patent to protect.
Include alternative output forms where appropriate
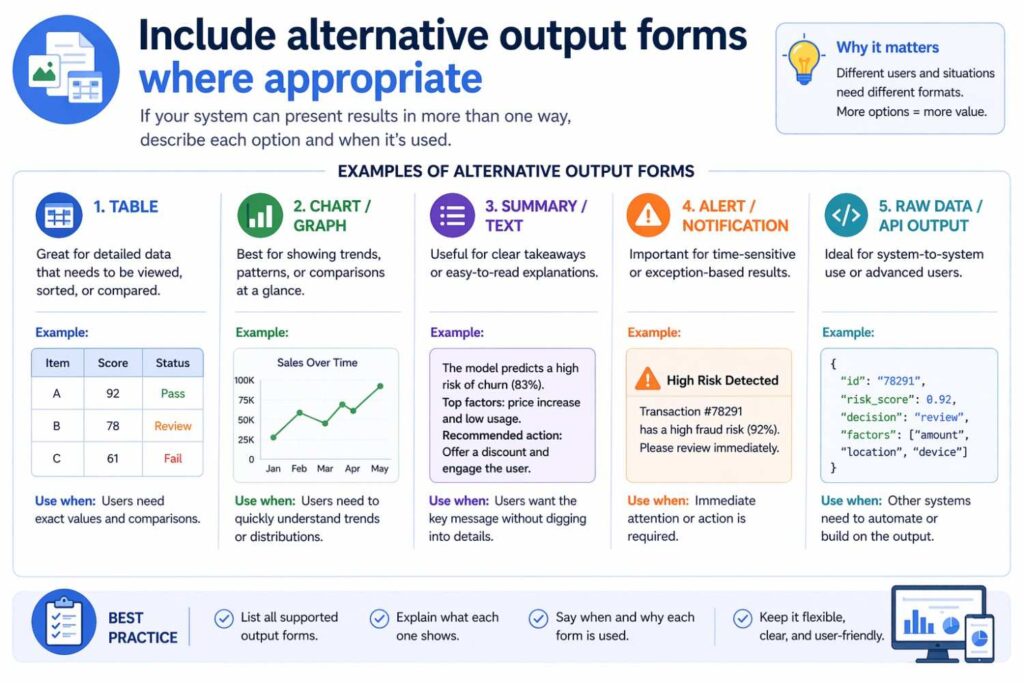
A lot of patents become too narrow because they describe only one exact output.
Maybe today your model outputs a binary class. Tomorrow it may output a ranked set. Maybe today it outputs a confidence score. Tomorrow it may output a confidence interval and an explanation. Maybe today it outputs one task suggestion. Tomorrow it may output a set of candidate actions.
If those variants are realistic, disclose them.
You can say the system may output a classification, a score, a ranked set, a structured object, a generated sequence, or another prediction derived from the input data. You can say the output may be used directly or may be transformed before use by a downstream module.
Do not make the disclosure meaningless by naming every output under the sun. Keep it tied to the invention. But give yourself room.
This is where smart drafting helps. You want the patent to cover what you built and what it is reasonably likely to become.
That is a big part of the value of working with PowerPatent. It helps founders capture the current invention while still leaving room for future versions, product expansion, and technical changes, with attorney review built in so you do not end up with a filing that is either too weak or too boxed in. You can see how that works here: https://powerpatent.com/how-it-works
A simple framework you can use
When you sit down to describe model inputs and outputs, use a plain framework.
For inputs, write down four things in sentence form.
What data or signals come in.
Where they come from.
How they are prepared or structured.
Why they matter to the prediction or generation.
For outputs, write down four things too.
What the model produces.
What that output means.
How it is formatted or organized.
What the system does with it.
That is enough to create a strong first draft.
Here is a plain example.
Weak version:
“Our AI takes customer data and predicts churn.”
Better version:
“The system receives customer account activity data including login frequency, usage duration, support interaction history, billing status, and feature adoption values. The system generates a customer feature representation from the activity data and provides the representation to a trained model. The trained model outputs a churn likelihood score for the customer account. A retention workflow module uses the churn likelihood score to determine whether to generate a retention prompt, schedule an outreach task, or suppress further action.”
That is already much better.
Now you can expand it by adding alternatives, timing details, confidence values, or segmentation behavior if needed.
How much detail is enough?
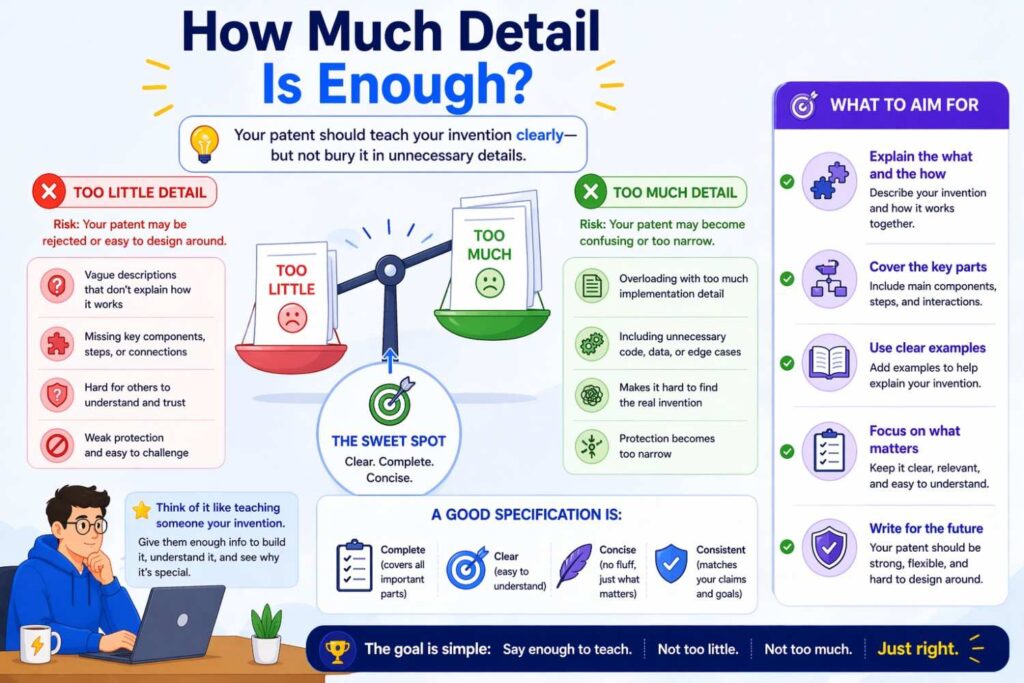
This is one of the hardest questions for founders.
Too little detail and the patent sounds generic.
Too much detail and the patent becomes fragile.
The right amount depends on the invention, but here is a practical test.
After reading your description, could a technical reader answer these questions?
What kind of information enters the model?
What important structure or processing is applied to that information?
What kind of result does the model produce?
How does that result affect the system?
If the answer is yes, you are likely in a good zone.
Notice what is not required.
You do not always need to provide full training details, exact model weights, or every numeric setting. You do not need to include source code. You do not need to lock the invention to one vendor tool or one exact library. You do not need to drown the reader in equations unless the math itself is the point.
What you do need is enough technical substance to make the invention understandable and usable, and enough breadth to avoid trapping yourself.
This is why DIY patent drafting is risky for complex AI systems. Founders often swing hard in one direction. Either they write like a pitch deck, or they write like an internal design document. Both can miss the mark.
The role of examples in a patent
Examples are your friend.
Not because you want to narrow the patent, but because examples help the reader understand what the general description means.
For inputs, examples can show typical sources, field values, representations, and optional variants.
For outputs, examples can show typical result types, confidence values, action triggers, and system use.
The trick is to present examples as examples, not as the only version.
Use language like “in some implementations,” “for example,” “in one embodiment,” or “in certain cases.”
That way, you can disclose detail without making the whole patent hinge on one exact flow.
Suppose your system uses a model to help inspect code changes.
You might describe the inputs generally as repository state data, code change data, execution history data, and issue history data. Then you can give examples: changed files, changed functions, test outcomes, stack traces, dependency graphs, or deployment metadata.
You might describe the outputs generally as one or more predicted risk values, suggested review actions, or identified affected components. Then you can give examples: a failure likelihood score, a ranked list of risky modules, a recommendation to run targeted tests, or a proposed reviewer assignment.
Examples give texture. They help the invention feel concrete without boxing it in.
Use consistent words throughout the application
This may sound small. It is not.
If you call something “interaction events” in one section, “user actions” in another section, and “behavioral signals” in a third section, that may create avoidable confusion unless those are meant to be different things.
The same goes for outputs. If you use “risk value,” “risk score,” “likelihood,” and “decision metric” without care, the draft can become messy.
Consistency matters because patents are legal documents, but even before that, they are technical stories. A clean story is easier to follow and easier to use later when drafting claims.
That does not mean you should repeat the same sentence again and again. It means your key terms should stay stable. Define the important concepts clearly, then use them in a disciplined way.
For example, you might decide that your system receives “event records,” generates “feature representations,” applies a “trained prediction model,” and outputs a “priority score.” Once you choose those phrases, use them steadily unless you have a reason to distinguish a subtype.
This is one of those quiet details that makes a patent feel strong.
Make room for variations without becoming vague
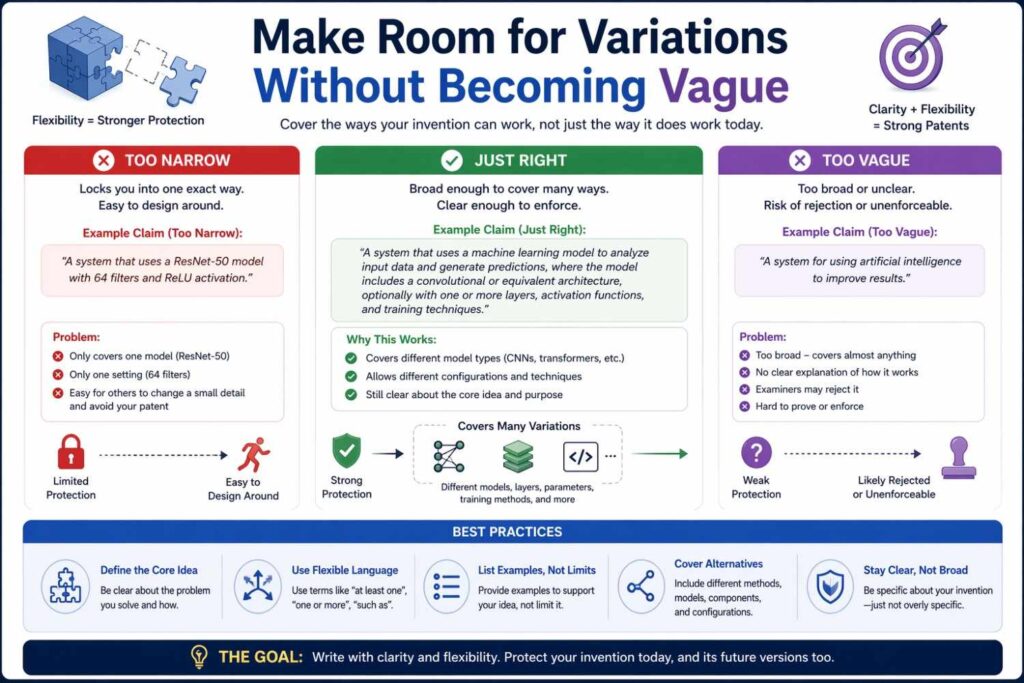
Founders often ask how to keep the patent broad while still saying something real.
The answer is not to be blurry.
The answer is to disclose one or more concrete implementations and then state sensible variations around them.
For inputs, this may mean saying that the model may receive one or more of several signal types, or that certain fields may be optional, or that the same information may be represented in different ways.
For outputs, this may mean saying that the model may produce a score, a classification, a ranking, or another action-enabling value derived from the processed input data.
For example, suppose your system matches workers to jobs. You might say the inputs include worker skill data, location data, schedule availability data, and task requirement data. Then you can add that skill data may be derived from profile fields, prior task completion data, or external certification data. You can also say the output may include a compatibility score, a ranked set of candidate workers, or a recommended assignment.
That gives breadth without losing substance.
Do not hide the invention behind the phrase “machine learning model”

This phrase shows up in too many weak AI patents.
Yes, you may need to use it. But it should not carry the whole burden of explanation.
If your patent says a “machine learning model” receives data and outputs a result, that does not tell the reader what is inventive.
The invention may live in the chosen inputs, the arrangement of inputs, the preprocessing, the output structure, the control logic around the model, the feedback loop, the way the outputs are used, or the training data organization.
So treat “machine learning model” as a component, not a substitute for detail.
Even if you do not want to lock yourself to a specific model type, you can still describe the model’s role in a meaningful way.
You can say it is configured to estimate a probability, generate a representation, rank candidates, identify a segment, generate a text sequence, or select an action based on processed inputs.
That is far better than leaning on the label alone.
If the invention uses embeddings, say what they represent
Embeddings show up everywhere now. User embeddings. Item embeddings. document embeddings. Code embeddings. Image embeddings. Session embeddings.
But the word “embedding” alone is not enough.
If the patent uses embeddings, explain what each one represents and how it is used.
Does a user embedding represent long-term preference behavior? Does a document embedding represent semantic content of a page? Does a code embedding represent a function or module? Does an item embedding represent a product in a recommendation space? Does a context embedding summarize recent conversation state?
Then say how the embedding is formed or obtained, at least at a useful level. Is it generated by an encoder, derived from prior interactions, retrieved from storage, or updated over time?
Then say what happens next. Is the embedding compared to another embedding, joined with other features, fed into a ranking model, or used to retrieve candidates?
This turns a trendy term into a technical disclosure.
If the output is a score, explain thresholds and actions
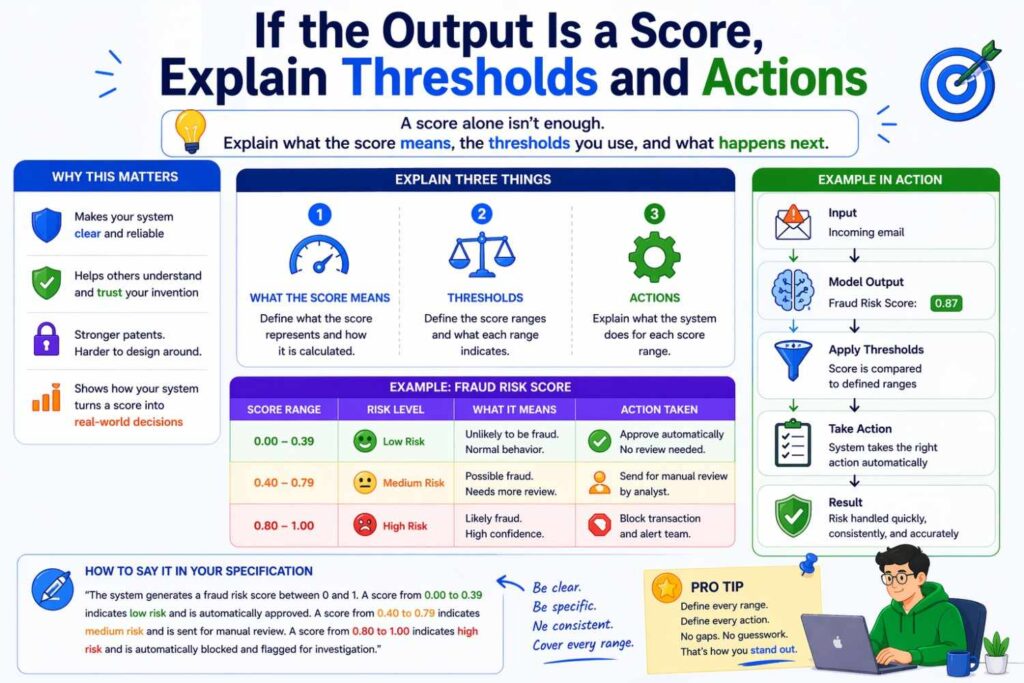
Scores are common outputs.
Risk score. Quality score. Intent score. Similarity score. Confidence score. Priority score. Relevance score.
If your model outputs a score, the patent gets stronger when you explain how the score is interpreted.
Is there a threshold? Are there multiple ranges? Does the score affect ranking? Does it determine whether a record goes to review? Does it change what appears in the interface? Does it control whether another model runs?
For example, a system may output a confidence score for extracted fields. Fields above a first threshold may be auto-filled. Fields between the first threshold and a second threshold may be highlighted for review. Fields below the second threshold may be suppressed.
That kind of detail can be very valuable because it ties the model output to concrete system behavior.
Likewise, if the output is a ranking score, explain whether the system sorts candidates based on it, combines it with constraints, or selects a top subset for presentation.
The output becomes more meaningful when it drives action.
If the output is generated text, show structure and use
A lot of AI products now produce text. That includes LLM systems, drafting tools, support assistants, coding tools, workflow agents, and many others.
If the output is text, do not just say “the model generates text.”
What kind of text?
What is the text for?
How is it constrained?
How is it used?
Generated text may be a summary, a command, a draft response, a structured field response, a code change suggestion, a label explanation, a query, or a task plan.
The more clearly you explain the role, the better.
Suppose your system helps with customer support. You might say the model outputs a response draft associated with a selected issue category and one or more cited account events, and that the response draft is presented in an agent interface for approval or editing.
Suppose your system extracts data into structured form. You might say the model outputs a set of text spans corresponding to target field values and a structured object that maps the field values to field identifiers.
Suppose your system generates code actions. You might say the model outputs a candidate code modification and a predicted effect summary associated with one or more tests.
This makes the output technically useful instead of merely creative.
If the output is a decision, explain whether it is final or advisory
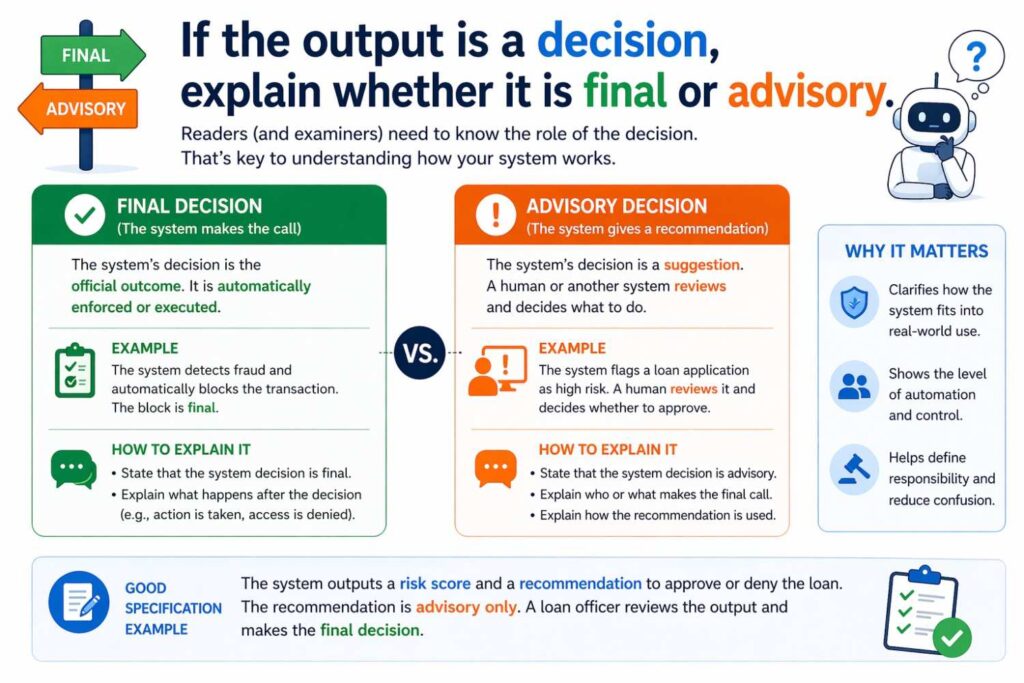
In many software products, model outputs do not act alone.
They may guide a human. They may propose an action. They may rank options. They may trigger review. They may participate in a larger decision process.
That distinction matters in a patent.
If the model output is advisory, say that. If it is determinative in some cases and advisory in others, say that too.
For example, an underwriting support system may output a risk estimate used by a reviewer. A network security system may automatically block traffic above a threshold but only flag traffic in a lower range. A content moderation system may remove clear violations automatically but route close cases for review.
These distinctions help make the invention believable and concrete.
They also help you avoid overclaiming what the system actually does.
Think about failure cases and edge cases

A surprisingly strong way to improve a patent is to describe how the system handles uncertainty, missing data, or low-confidence outputs.
Real systems face messy input. Signals may be missing. Data may conflict. A sensor may fail. A document may be low quality. A user prompt may be incomplete. An output may be uncertain.
If your system has a smart way to deal with those conditions, that may be part of the invention.
Maybe the model uses fallback inputs. Maybe the system estimates confidence and changes behavior accordingly. Maybe it requests more data. Maybe it routes to a different model. Maybe it triggers human review. Maybe it fills missing features from history. Maybe it generates partial outputs.
Those details can help differentiate your system from simpler generic approaches.
For example, a document extraction system may output extracted values together with source-region links and confidence values, and may withhold auto-population of fields when confidence falls below a threshold. A robotics system may reduce action range when sensor confidence drops. A coding assistant may request clarifying repo context before suggesting a patch.
That kind of behavior often matters in the real product. So do not leave it out.
Show the system flow around the model
Remember, a patent is not a Kaggle entry.
You are not trying to prove benchmark accuracy. You are describing an invention.
That means the best disclosure often includes a simple system flow around the model.
Data arrives. It is processed. The model receives input. The model produces output. The system acts on the output. Optionally, feedback is collected and used for later updates.
That flow can be described in text and often in figures too, but even in plain writing it helps a lot.
Without the flow, the model can sound isolated. With the flow, the model becomes part of a real machine.
This is especially important for patent eligibility issues in software and AI. A concrete technical flow can help show practical application, not just abstract data analysis.
You do not need to use legal language to understand the point. The more your patent describes a working system that handles real inputs and performs real outputs that change system behavior, the better.
The difference between “what the model sees” and “what the claim may say”
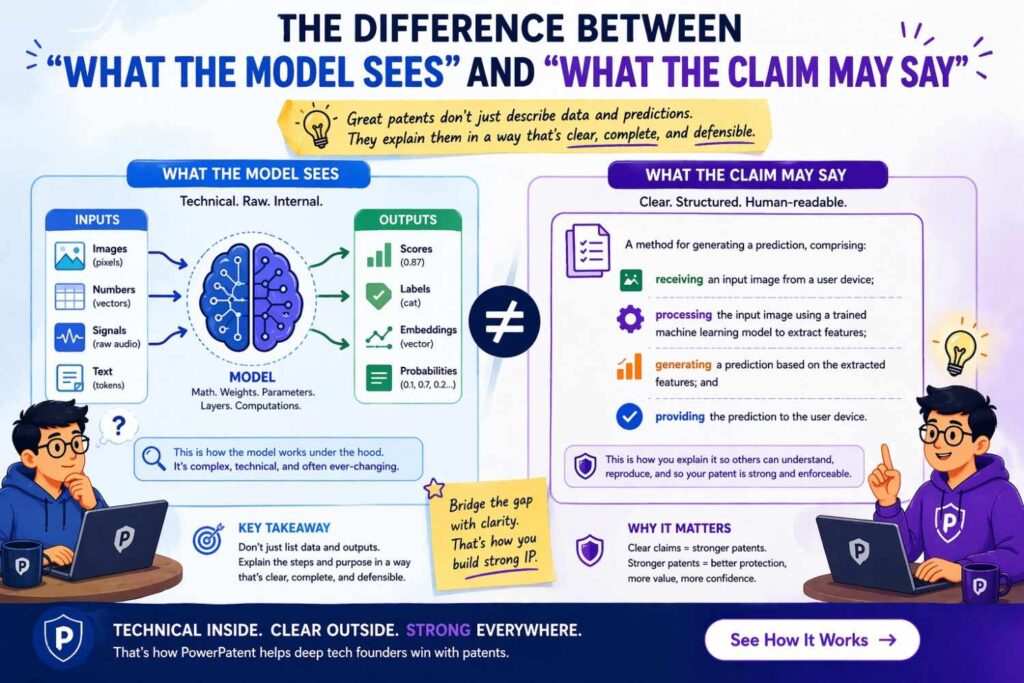
Here is something important.
The patent specification should usually disclose more than the final claims will say.
Founders sometimes think they need to draft every sentence as a claim. That is not the goal.
The goal of the detailed description is to give a full enough picture that claims can later be written at the right level.
For example, the specification might explain several possible input forms, several optional preprocessing steps, and several possible outputs. The claims might then focus on the most important combination or the most defensible abstraction.
That means when you describe model inputs and outputs, you should think expansively. Capture the real invention and reasonable variants. Do not only write the one sentence you think belongs in claim 1.
This is one reason working with a strong platform matters. You want to preserve the technical richness now so the filing has room to work later. That is a big part of what PowerPatent helps teams do: turn product reality into a patent-ready record while it is still clear, without wasting weeks or losing control of the process. The overview is here: https://powerpatent.com/how-it-works
A worked example: recommendation system
Let’s walk through an example in plain language.
Suppose you built a recommendation system for a B2B SaaS platform. It helps suggest the next best workflow step for a user inside the app.
A weak description would say this:
“A machine learning model analyzes user data and recommends actions.”
That is nearly useless.
A stronger description might look like this:
The system receives interaction data associated with a current workspace session, including page visits, control selections, time spent in interface regions, recent object edits, and task completion history.
The system may also receive workspace metadata, user role data, team activity data, and object state data associated with records currently shown in the interface.
A preprocessing component groups the interaction data into a session representation and generates one or more feature values reflecting recency, frequency, sequence position, and object relationship state. The preprocessing component may further generate embeddings representing the current user, the workspace, and candidate workflow actions.
A trained model receives the session representation, the feature values, and the candidate action embeddings and outputs one or more predicted action relevance values.
A ranking component orders candidate workflow actions based on the predicted action relevance values and optionally applies one or more business constraints, such as permission rules or object availability rules.
A user interface component presents one or more selected workflow actions in a context-sensitive panel within the application interface. In some implementations, the system updates the presented workflow actions in response to new interaction events during the same session.
See how much better that is?
Now the reader knows what the inputs are, how they are structured, what the model produces, and how the system uses the outputs.
And you still have room to vary the model type.
A worked example: document extraction system
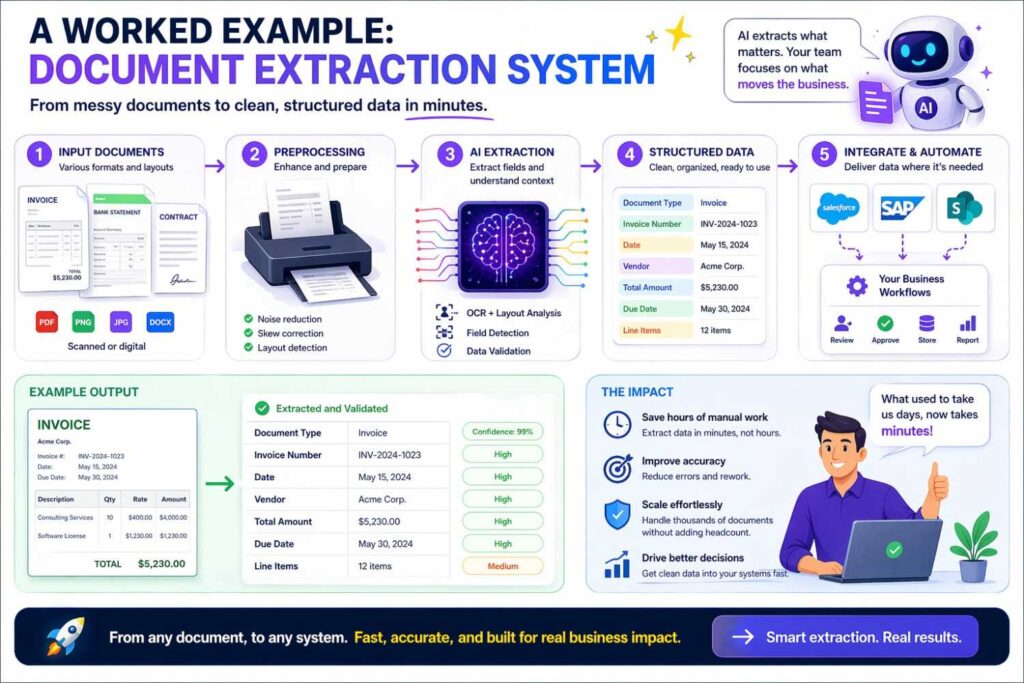
Now imagine a document AI system that extracts contract terms.
Weak version:
“The AI reads documents and extracts key fields.”
Better version:
The system receives a digital document including page image data and recognized text data. The recognized text data may include text tokens, token positions, line associations, and page identifiers. The system may further identify section headings, table regions, signature regions, and layout boundaries.
A feature generation component creates input representations for a trained extraction model based on textual content, token position values, line grouping values, and layout relationships among tokens and regions.
The trained extraction model outputs one or more field values associated with target contract terms, such as effective date values, payment term values, renewal term values, and termination notice values.
In some implementations, the trained extraction model further outputs confidence values and source-region identifiers associated with the field values. A validation component uses the confidence values to determine whether to automatically populate a structured contract record, highlight one or more fields for review, or request additional user confirmation.
Again, this is stronger because the inputs and outputs are both meaningful and connected to system behavior.
A worked example: predictive maintenance
Let’s do one more.
Weak version:
“The model predicts equipment failure from sensor data.”
Better version:
The system receives time-stamped operating data from industrial equipment, the operating data including vibration values, temperature values, pressure values, current draw values, and mode-state values associated with a machine identifier.
A preprocessing component aligns the operating data across sensors, groups the operating data into rolling time windows, and generates feature representations reflecting changes in signal level, signal variability, cross-sensor relationships, and deviation from baseline operating behavior.
A trained prediction model receives the feature representations and outputs a fault likelihood value for a future interval associated with the industrial equipment. In some implementations, the trained prediction model further outputs a predicted fault type or a remaining-useful-life estimate.
A maintenance control component uses the output to generate an alert, schedule an inspection, modify an operating parameter, or store a machine health state for later review.
That tells a real technical story.
A worked example: LLM workflow assistant
Now let’s look at a product many founders are building today.
Suppose you built an LLM-based internal assistant that helps employees complete tasks across tools.
Weak version:
“The assistant uses a language model to answer user questions and take actions.”
Stronger version:
The system receives a task request from a user device, the task request including natural language text specifying a desired outcome. The system further retrieves workspace context associated with the user device, including one or more prior messages, task records, document excerpts, calendar values, and permission data. In some implementations, the system also retrieves tool schemas, output formatting rules, and policy constraints defining permitted actions.
A context assembly component generates a structured prompt representation including the task request, the retrieved workspace context, and one or more action constraints.
A language model receives the structured prompt representation and outputs one or more candidate action plans, one or more tool call parameters, or a draft response text sequence. A control component evaluates the output against the policy constraints and either executes a selected tool call, presents an approval interface to the user, or requests additional information. In some implementations, the system stores the generated output and the corresponding result as part of a task memory used in later requests.
This is much better because it shows the inputs around the LLM, the actual output forms, and the system logic that turns output into action.
That outer system is often where the patent value really is.
How to capture your inputs and outputs from the product team
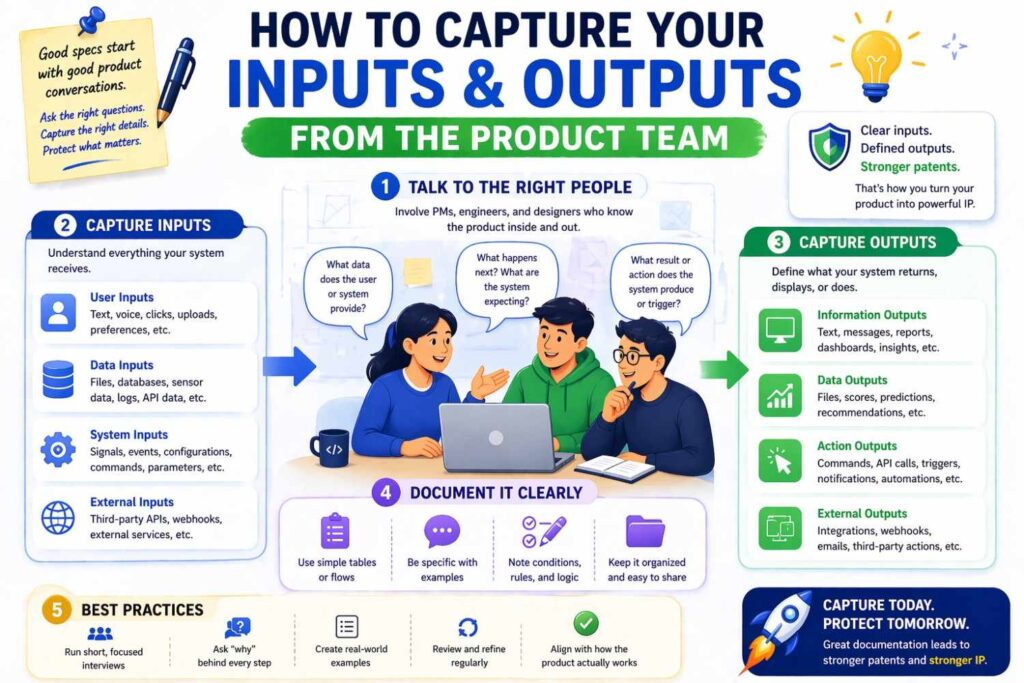
If you are a founder or engineer, you do not need to start by writing patent prose.
Start by interviewing the product and engineering reality.
Ask your team simple questions.
What does the model actually consume at run time?
What data arrives first?
What gets transformed before model inference?
What optional context matters?
What exact thing does the model emit?
Who or what uses that output?
What happens after that?
What alternate inputs and outputs have we used or considered?
Where does confidence matter?
What would still be true if we changed the underlying model next quarter?
Those answers are gold.
Then you can convert them into patent language.
This is why a good patent process should feel more like technical capture and less like legal theater. Founders should not have to guess how to turn working systems into strong disclosures. PowerPatent was built to make that part much easier, so the invention comes from your actual product and engineering details instead of a slow back-and-forth that drains time and misses the point. Here is the process: https://powerpatent.com/how-it-works
A useful drafting pattern for inputs
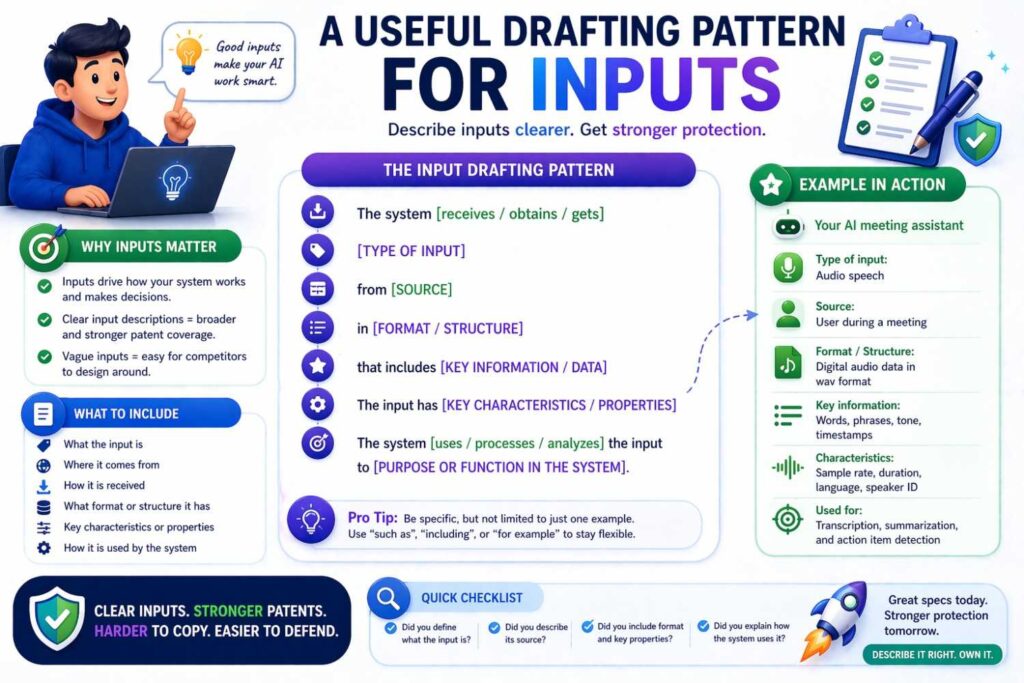
Here is a pattern that works well in many cases.
Start with the receiving step.
“The system receives…”
Then name the sources and data types.
Then explain optional processing.
Then explain what representation is provided to the model.
Then explain the purpose of that representation.
For example:
“The system receives transaction event data associated with a payment request, the transaction event data including merchant identifier data, account history data, device state data, geolocation data, and event timing data. A preprocessing component normalizes the transaction event data, derives one or more behavioral features from prior account activity, and generates a transaction representation. The transaction representation is provided to a trained risk model to estimate a fraud likelihood associated with the payment request.”
That pattern is clean and adaptable.
A useful drafting pattern for outputs
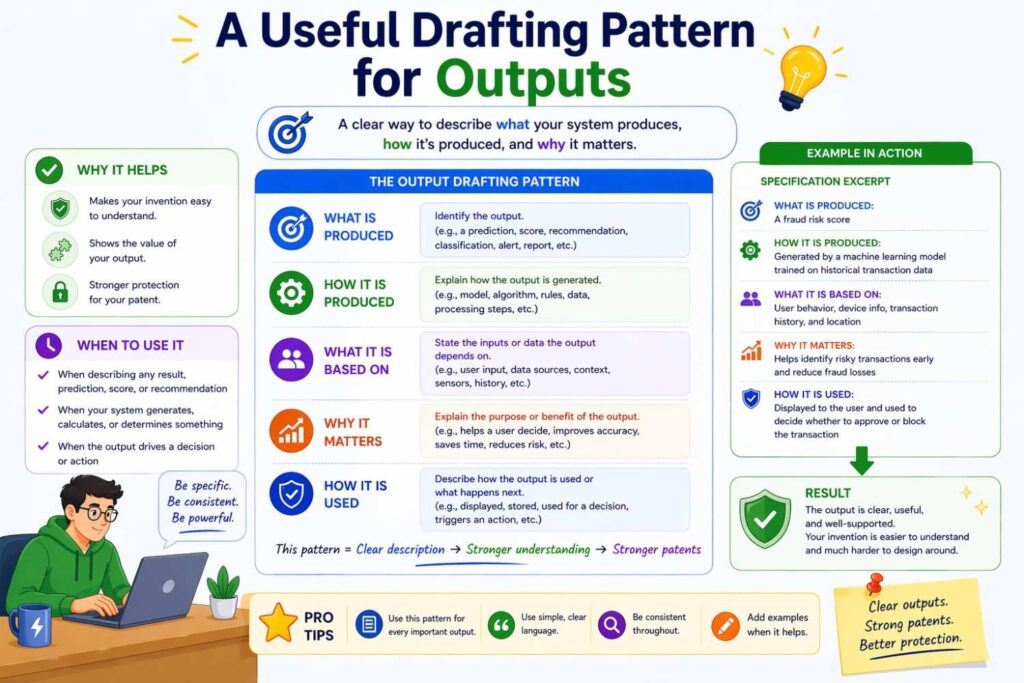
A similar pattern works for outputs.
Start with what the model produces.
Then explain the meaning.
Then explain optional forms or companion values.
Then explain what downstream component uses it.
For example:
“The trained risk model outputs a fraud likelihood score associated with the payment request. In some implementations, the trained risk model further outputs a suspected fraud category and a confidence value. A decision component compares the fraud likelihood score to one or more threshold values to determine whether to approve the payment request, deny the payment request, or route the payment request for manual review.”
That is the kind of sentence that carries real weight.
Words that often weaken the draft
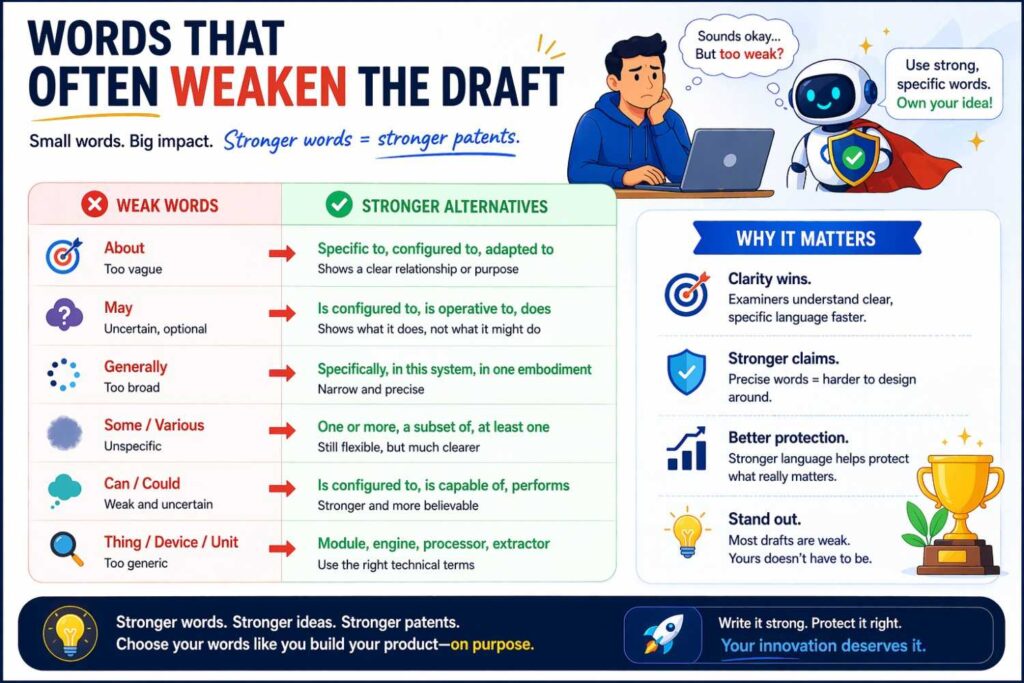
There are certain words and habits that make patents sound empty.
Words like data, information, context, signal, result, output, content, or event are not bad by themselves. But when used alone, they often hide the real story.
“The system receives data.” What data?
“The model uses context.” What context?
“The system outputs a result.” What result?
You do not need to ban these words. Just do not let them stand alone.
Pair them with specifics.
Also be careful with hype words like intelligent, smart, advanced, cutting-edge, powerful, adaptive, or state-of-the-art. These words do almost nothing for patent quality. Often they make the draft weaker because they replace explanation with applause.
A strong patent does not brag. It shows.
Words that often help

Some kinds of words make AI system descriptions much stronger.
Words that describe source. Such as user device, sensor, repository, workspace, service log, page image, transaction record, or tool schema.
Words that describe structure. Such as sequence, window, feature representation, embedding, token set, graph, candidate set, ranking, or structured object.
Words that describe action. Such as estimate, classify, rank, generate, identify, route, trigger, update, select, or present.
Words that describe relationship. Such as associated with, linked to, aligned with, derived from, based on, relative to, corresponding to, or grouped by.
These words help the reader picture system behavior.
How claims and description support each other
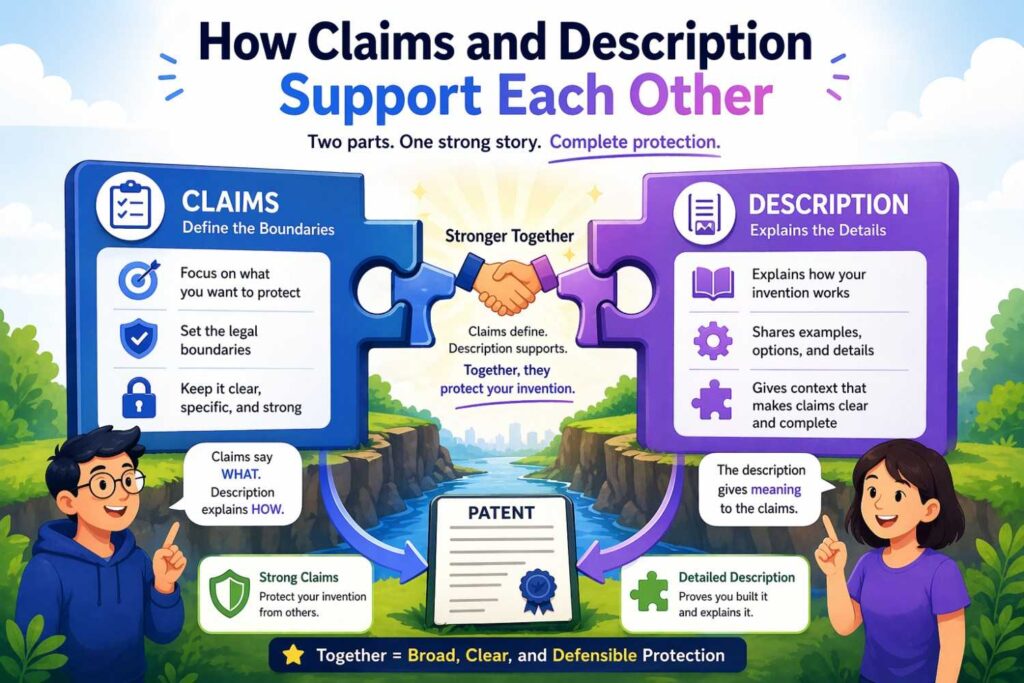
Even though this article is mainly about the description section, it helps to understand why this work matters for claims.
Claims need support.
If you want a claim that says the system receives a sequence of events and outputs a ranked set of actions, the specification needs to support that.
If you want a claim that says the system uses layout relationships in a document and outputs field values with confidence values, the specification needs to support that.
If you want a claim that says the system uses multimodal inputs or intermediate representations, the specification should explain those.
The better your input and output disclosure, the more options you create later.
That is why this is not busywork. It is leverage.
What to do when the model changes fast
This is common in startups.
You may start with gradient boosted trees, then move to a transformer, then add retrieval, then replace part of the stack with a smaller model, then move some logic outside the model.
So how do you write a patent that survives this?
Focus on stable invention layers.
What input relationships matter regardless of model vendor or architecture?
What output forms matter regardless of exact implementation?
What system flow matters even if the inner model changes?
What feature preparation or routing logic is part of the product’s core value?
What action logic around the output is likely to stay?
These stable layers often make the best patent material.
Then disclose multiple model options where appropriate. Say the model may include one or more classifiers, sequence models, ranking models, language models, neural networks, probabilistic models, or other prediction components. But do not stop there. Anchor the invention in the concrete input-output behavior and system use.
That way, you protect the idea in a durable way instead of tethering everything to today’s stack.
A note on training data and labels
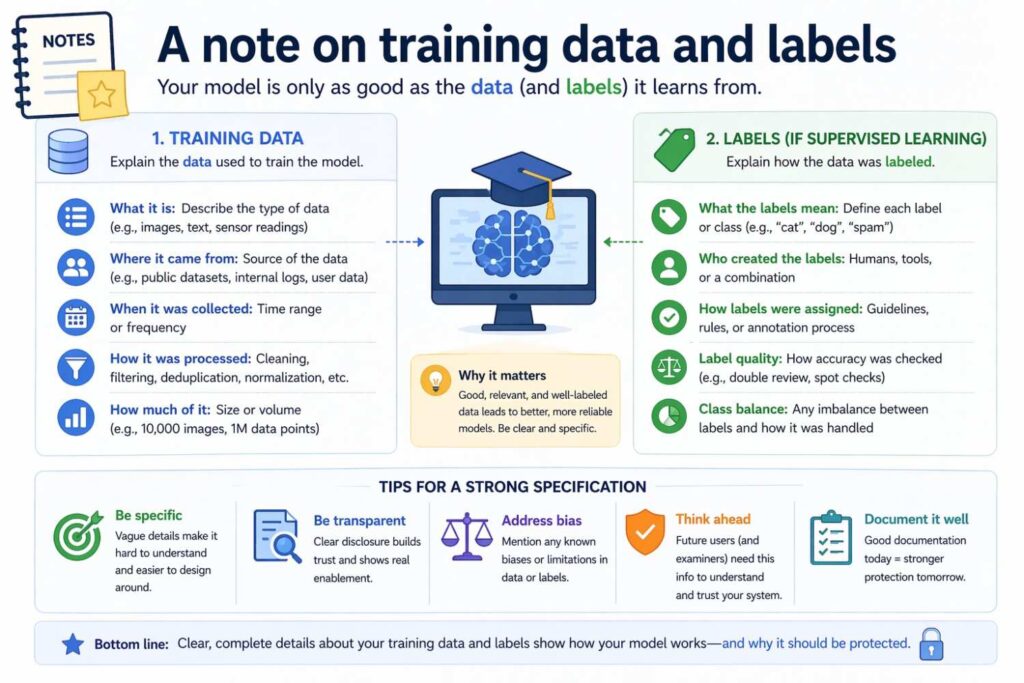
Sometimes the inputs and outputs you need to describe are not only run-time inputs and outputs. Sometimes training-time details matter too.
For example, your invention may involve generating training labels from delayed outcomes, creating synthetic pairs, aligning human feedback with action traces, or learning from a special mix of weak supervision and user corrections.
If those parts are important to what is new, disclose them.
Likewise, if the output of one training stage becomes the input to another stage, that may matter.
But keep the main focus on what the system does in use, unless the training pipeline itself is the invention.
Avoid turning the patent into a research paper

A lot of AI founders make this mistake because they are used to technical papers.
They include too much about benchmarks, model family debates, and narrow experiment detail, while skipping practical system flow.
A patent is different.
You do not need to prove novelty through charts and literature tone. You need to describe your invention clearly and broadly enough to support meaningful claims.
That means it is often better to explain the inputs, transformations, outputs, and system use in plain engineering language than to spend pages on academic framing.
Simple is powerful here.
Make the reader see the product
This may be the best test of all.
After reading your patent description of inputs and outputs, can the reader picture what the product is doing?
Can they imagine data arriving?
Can they see what the model receives?
Can they see what the model produces?
Can they see how the output changes the product?
If yes, you are on the right path.
If not, you probably need to replace generic phrases with real system language.
A founder-friendly checklist in paragraph form

Before you finalize your draft, read your input and output sections and ask yourself a few things.
Have you named the real sources of the inputs, not just called them data? Have you explained the important content of those inputs in simple terms? Have you shown how the system structures, prepares, or combines the inputs before the model uses them? Have you explained what the model output actually is and what it means?
Have you shown what the system does with the output? Have you captured likely variations without drifting into empty vagueness? Have you stayed broad enough to cover future product versions? Have you avoided locking the invention to one exact implementation unless that exact choice is the point?
If the answers are mostly yes, your draft is likely getting much stronger.
Why this matters for startup speed
A weak patent is not just a legal problem. It is a speed problem.
If your filing does not capture the right input-output story now, you may have to fix it later when the product has already changed, the details are harder to recover, and the invention has spread across more systems.
That creates delay, cost, and stress.
The best time to capture this is while the team still clearly knows what the model sees, what it produces, and why that matters.
That is exactly why modern teams need a better way to do patents. PowerPatent helps founders move while the technical details are fresh, using software designed for startup workflows, with real attorney oversight so the final work is not just fast, but solid. If that sounds like the way you want to protect your AI product, start here: https://powerpatent.com/how-it-works
The plain truth
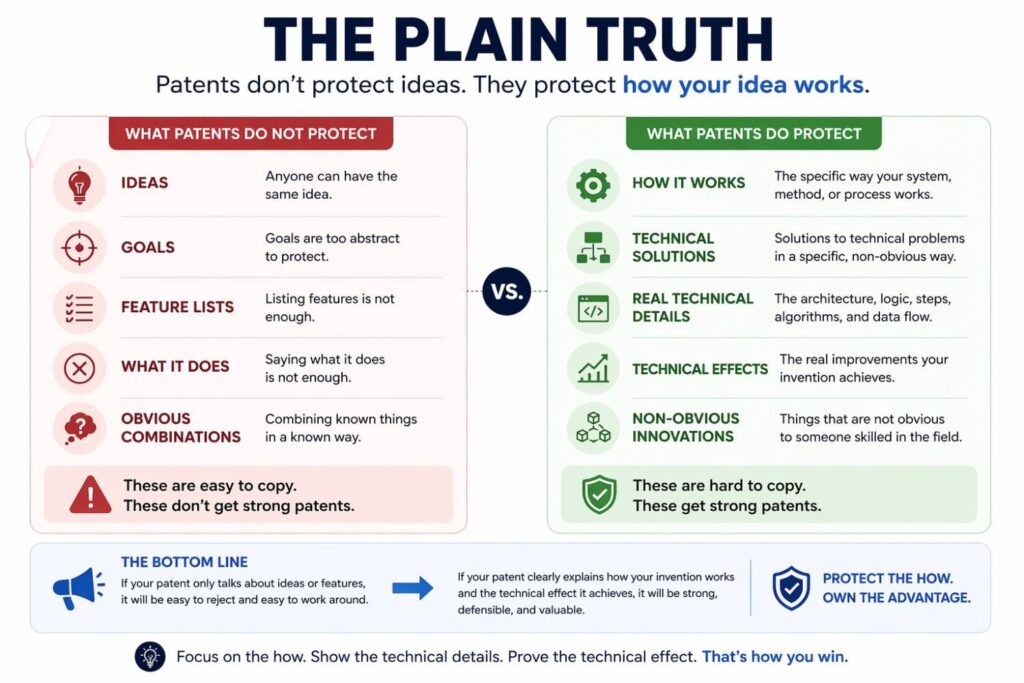
Describing model inputs and outputs in a patent is not about sounding impressive.
It is about being clear.
It is about showing what enters the system, what happens to it, what leaves the model, and why that matters in the real product.
The strongest AI patents usually do not rely on magic words. They rely on clear technical storytelling.
They explain the source and meaning of inputs.
They explain the structure and purpose of representations.
They explain the form and meaning of outputs.
They explain the downstream system behavior.
They leave room for variants.
They stay connected to the actual invention.
That is the work.
And when you do it well, your patent becomes much more than a document with AI language in it. It becomes a real asset built around the real technical value of your product.
If you are building something important, do not leave this part fuzzy. Capture it clearly. Capture it early. And do it in a way that gives your company room to grow.
PowerPatent is built for exactly that kind of founder: someone building real technology who wants strong protection without the old slow, painful process. See how it works here: https://powerpatent.com/how-it-works
Final takeaway
When you describe model inputs and outputs in a patent, think like a builder explaining a working machine.
Say what comes in.
Say where it comes from.
Say how it is shaped into a useful model input.
Say what the model produces.
Say what that output means.
Say what the system does next.
Do that with enough detail to make it real, and enough flexibility to cover what comes next.
That is how you move from vague AI patent language to a disclosure that can actually protect what you built.
And for founders who want to make that process faster, clearer, and safer, PowerPatent is worth a close look: https://powerpatent.com/how-it-works