Patents are messy. Not because they’re bad—but because the world is big, inventors are everywhere, and people describe the same thing in different ways.
If you’re trying to make sense of a huge stack of patent references, the same invention can show up again and again under different names, different countries, or different codes. It’s like trying to read a hundred different versions of the same book—with slightly different covers and titles.
Why Duplicates Happen in Patent Data (And Why It Matters)
Patent data isn’t clean. It’s not just that there’s a lot of it—it’s that the same invention can appear multiple times across countries, databases, formats, and naming conventions.
This isn’t just a headache for analysts. It creates serious problems for startups, IP teams, and anyone making decisions based on incomplete or cluttered data.
How the Same Invention Gets Counted More Than Once
When an inventor files for protection in multiple countries, each country gives that application its own number, date, and label. Even if it’s literally the same invention, it gets treated like a different record in most systems.
This means you’ll often see five or six versions of the same idea—scattered across your reference list—without an obvious way to tell they’re connected.
Language and Formatting Differences Multiply the Noise
Every patent office has its own way of structuring records. The same inventor name might be spelled a dozen ways. One database might include kind codes while another omits them.
Some countries include middle initials, others don’t. Even small differences—like commas or abbreviations—can create extra entries that slip through traditional matching tools.
Why Your Results Are Only as Good as Your Cleaning
If you’re doing prior art search, competitive landscaping, or freedom-to-operate analysis, this duplication directly affects your decisions. Miss a duplicate, and you might think there’s more risk than there really is.
Miss a family connection, and you might underestimate a competitor’s strength. Either way, your strategy is built on shaky ground.
The Hidden Cost of Overlapping References
Many teams try to “just deal with it” by eyeballing or filtering manually. That works when you’re reviewing 10 references. But once you cross into the thousands—or try to automate downstream actions—it breaks.
Every duplicate slows your review, drains resources, and increases the chance of human error.
Filing Decisions Can Go Off Track
When you’re rushing to file and the pressure is on, duplicate data can lead to overcautious or misinformed calls.
You might delay a filing because you think something is covered—when it’s just the same reference, listed three times.
Or worse, you might assume there’s no prior art when a duplicate disguised a real risk. Either way, bad data equals bad decisions.
Real-World Example: The Same Patent, Five Appearances
Imagine you’re evaluating a smart sensor technology and see five different references. They have slightly different titles, authors, and formats.
You spend time reviewing all of them—only to realize they’re all versions of the same original patent, filed in the US, Japan, Europe, Korea, and China.
That’s 80% wasted time, five records cluttering your system, and a false sense of market saturation.
You Can’t Automate If You Don’t De-Dupe
Many teams are trying to automate IP review and strategy. But here’s the catch: your automation is only as smart as your data.
If duplicates are flooding your system, your alerts will be off, your analytics will misfire, and your dashboards will mislead. Cleaning up the duplication isn’t optional—it’s foundational.
For Startups, Every Hour Matters
If you’re running a startup, you don’t have weeks to sort through messy records. You need clear, clean signals to make fast calls. De-duping isn’t just about being tidy.
It’s about reclaiming time, moving quickly, and filing with confidence. And in early-stage tech, speed isn’t a luxury—it’s a weapon.
Action Step: Build Cleaning Into Your Workflow Early
Don’t wait until you’re overwhelmed to clean your data.
Whether you’re using in-house tools or working with platforms like PowerPatent, make sure your reference handling includes de-duplication as a default step—not an afterthought.
The earlier you standardize and streamline your input, the faster and more accurate every downstream process becomes.
The Compounding Effect of Clean Data
Once you start working with deduped references, everything changes. Searches get faster. Reviews get sharper. Filings get more strategic. You see gaps more clearly.
You find opportunities you might’ve missed. And most importantly, you stop wasting time on the same thing twice.
What Patent Families Really Mean (And How to Group Them Right)
Patent families sound simple. A family is a group of patent applications that all come from the same original invention.
But once you try to group these families across different countries, systems, and naming rules, things get messy—fast.
Understanding how families work is key to cleaning your data, cutting down duplicates, and making smarter decisions about your IP strategy.
One Invention, Many Paths
Let’s say you file a patent in the US. A few months later, you file the same invention in Europe and Japan. These aren’t new inventions. They’re just the same idea being protected in different regions.
But every system gives each of those filings its own application number, kind code, and metadata.
When you’re looking at your patent list, those three filings might look like three separate inventions. But they’re not. They’re one family—and treating them that way can save you time and reduce confusion.
The Challenge of Incomplete Grouping
Most raw patent datasets don’t come pre-grouped by family. Even when they do, the groupings aren’t always reliable. They might include only direct filings and miss continuations.
They might group too broadly and pull in unrelated records. You can’t assume the family data is clean unless you’ve seen how it’s built.
That’s why smart de-duping tools don’t just look at numbers—they look at relationships.
At PowerPatent, for example, we build a custom family structure based on priority claims, filing dates, and legal status to catch connections most systems miss.
Priority Dates Are Not Enough
A lot of people try to group families by matching the earliest priority date. That works—sometimes. But in the real world, two separate inventions can have the same priority date.
Or one invention might evolve into multiple filings that don’t share a clean priority chain.
You need a more flexible way to understand family ties. Not just by date, but by legal relationships, shared inventors, and technical content.
Without that, you risk grouping the wrong filings together—or missing real family links that matter for your strategy.
Regional Families vs. Global Families
Some systems group patent families based on a region. So you’ll have a “European family,” a “US family,” and maybe a “PCT family.” That’s helpful, but it misses the global picture.
If you’re trying to understand true coverage—how far an invention spreads—you need to unify those regional families into one global view.
Startups especially need this clarity. If you’re trying to decide whether to file in a new market, you don’t want to be misled by region-based clusters.
You want to know: is this already protected somewhere else? Who’s behind it? How broad is the real footprint?
The Risk of Family Blind Spots
If your tools can’t track families clearly, you might think you’re safe to file—when in fact, a version of that invention already exists under a different jurisdiction or title.

Or you might think a competitor has five strong inventions, when they really just filed the same one in five countries.
These blind spots can slow you down or worse—get you into legal trouble. Filing over an existing family means wasted fees, possible rejections, and downstream conflicts.
Why Family De-Duping Is About Strategy, Not Just Cleanup
Grouping by family isn’t just a housekeeping task. It’s how you make better strategic calls. If you’re trying to do freedom-to-operate, you want to know how far each invention reaches.
If you’re trying to scout competitors, you want to know whether their filings are deep or just wide. If you’re pitching investors, you want to show true white space—not duplicated noise.
Action Step: Ask How Your Tool Defines a “Family”
If you’re using a patent search or analytics platform, don’t just assume the family grouping is correct. Ask: What counts as a family? Are regional filings grouped together?
Are continuations included? Are legal relationships tracked? If the answer is unclear, your results might be too.
PowerPatent makes this simple. Every reference is checked against a smart family matching engine that looks beyond surface-level data. So you get one clean view of each invention—no matter how many forms it takes.
Your Edge Comes from Clarity
When your family groupings are clear, your reviews become faster. Your strategies become sharper. You see through the fog and spot patterns your competitors miss.
And most importantly, you don’t get tripped up by the same idea showing up again and again under different clothes.
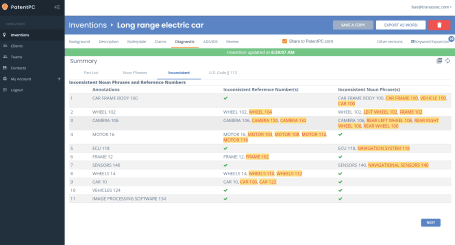
The Role of Kind Codes: One Invention, Many Faces
Even if you clean up duplicates and group by patent families, there’s another layer that trips people up—kind codes.
These small, often overlooked letter-number combos at the end of a patent number carry a lot of weight. They tell you what stage a patent is at, what type of document it is, and sometimes even what rights it holds.
But if you don’t know how to read them—or you don’t account for them in your system—you’ll end up staring at a pile of unnecessary duplicates.
What Kind Codes Actually Mean
A kind code is usually a letter or a letter and number added to the end of a patent publication number. It tells you what version of a document you’re looking at.
For example, in the U.S., a patent application might be published as US20230123456A1, where “A1” means it’s a published application.
Later, if it gets granted, it becomes US12345678B2, where “B2” means it’s a granted patent with a second publication.
The kicker? These two documents may contain 90% of the same content—but they show up as separate entries.
If your tools or systems don’t know how to collapse kind codes, you’ll end up reviewing the same invention twice (or more).
Why Kind Code Collapsing Matters for Startups
When you’re reviewing prior art or planning a filing, kind code duplication can make it look like there’s more coverage than there actually is.
You might think there are multiple filings blocking your path—when really, it’s just one patent in different stages of life.

For startups, every delay in filing is a missed edge. If you’re hesitating because of “too much prior art,” you need to be sure that art isn’t just a bunch of kind code variants.
De-duping kind codes helps you move forward faster—with more confidence and less clutter.
Kind Code Confusion Can Lead to Costly Mistakes
Let’s say you’re analyzing a market space. You pull data from multiple countries. You filter by keyword. You think you’ve got a clean list of inventions to study.
But five of those documents? They’re the same application, just published at different stages, under different codes.
If you don’t know how to collapse kind codes—or your tool doesn’t do it for you—you waste time, money, and focus on checking the same thing over and over again.
Worse, you might assume there’s more competition in the space than actually exists, steering you away from opportunities that are still wide open.
Not All Kind Codes Are the Same
Every country has its own kind code system. What “A1” means in the U.S. might not be the same in Japan or Europe.
Even within one country, codes can change depending on legal status, reissues, or corrections.
That’s why true kind code collapsing doesn’t just match codes—it understands what they represent.
It sees the lifecycle of the patent and knows when two documents are really just stages of the same invention.
Action Step: Look Past the Code, Focus on the Invention
When reviewing references, don’t stop at the number. Look at what the kind code is telling you. Is this an application or a grant? Is it a first publication or a later revision?
What country is it from, and how does that system use kind codes?
Better yet, use tools that handle this for you. PowerPatent automatically recognizes and collapses kind codes across jurisdictions.
So when you’re building your reference set, you only see what matters—the real invention behind the label.
Why Kind Code Collapsing Is Essential for Automation
If you’re building automated systems around patent data—alerts, dashboards, competitor tracking—you need to account for kind codes.
Otherwise, your systems will ping you five times about the same filing. Your dashboards will inflate patent counts. Your tracking will be off.

Cleaning kind codes upfront keeps your automation sharp. It ensures that every insight, every alert, every metric you track is based on real, non-redundant data.
Clean Kind Code Data Leads to Sharper Strategy
Once you remove kind code duplicates, you can think more clearly. You can compare apples to apples. You see who’s really filing new inventions, not just pushing the same one through multiple stages. You focus on substance, not noise.
For founders, this translates to smarter decisions: where to file, how to differentiate, when to pivot, and what risks are actually worth addressing.
Alias Matching: The Hidden Trouble with Names and Numbers
You’ve cleaned up families. You’ve collapsed kind codes. But there’s one more layer of mess that throws off even the best patent systems—aliases. The same company can appear under five different names.
The same inventor might be listed in slightly different ways. The same application might use different formats depending on the country or database.
This is where alias matching comes in. And it’s often the quietest troublemaker in the patent world.
Why Alias Confusion Slows You Down
Imagine you’re searching for all patents by a fast-growing robotics startup. You enter their name, and you find a few records. But what you don’t see? Their earlier filings under a former name.
Or the records where the name is slightly misspelled. Or where it’s abbreviated. Or where they used a shell company to file discreetly.
Without proper alias matching, your picture of the landscape is incomplete. You miss early filings. You miss ownership changes. You miss competitive signals. In short—you miss what matters.
The Real-World Impact of Bad Aliases
Let’s say you’re preparing a freedom-to-operate opinion. You check all the references by a known competitor. But they’ve filed some patents under an R&D sub-brand.
Or through a foreign partner. If you don’t match those aliases, you walk into false confidence. You think you’re in the clear when you’re not.
Or worse—you might see the same filing three times under different name formats, and think there are more players in the space than there really are.
You hesitate to file, or delay entering a market, because of ghost competition created by bad alias data.
Names Are Never Just Names
In patents, names are data points. But they’re not clean. “Apple Inc.” might appear as “Apple,” “Apple, Inc.,” “Apple Computer,” or “Apple Technologies.” Inventors might use initials on one form and full names on another.
Databases might cut off middle names or reverse name order altogether.
And then there’s translation. A Korean inventor’s name might be spelled differently in U.S. and Korean records. Without alias logic, these all get treated like different people.
Why This Matters Even More for Startups
If you’re a startup, you’re likely evolving fast. You might rebrand. You might spin up IP holding companies.
You might file under stealth or contract firms. If you don’t keep alias tracking tight, your own filings can become hard to track—even for your team.
And if you’re watching a competitor? You need to see their whole strategy, not just the part they put under their headline brand.
PowerPatent Solves Alias Confusion from Day One
Our system doesn’t just read names—it understands them. It uses smart algorithms to link common formats, legal entities, and naming conventions across jurisdictions.
If “Acme AI LLC” also files as “Acme Artificial Intelligence” or “Acme Innovations,” we link it. So you get one clean view of who’s doing what.
This saves you hours of manual cleanup. But more importantly, it gives you real confidence that you’re seeing the full picture—before you make a filing or pick a direction.
Action Step: Don’t Rely on Exact Name Matches
When reviewing data or running searches, don’t assume that the same name means the same entity—or that a slightly different name means a different one.
Use tools that handle alias matching for you. If you’re building your own database, start tagging known aliases early.
And always double-check early filings. A lot of companies file their first patents under generic or experimental names. That history is gold when you’re scouting threats or trends.
Alias Matching Is the Glue That Pulls the Whole Picture Together
Family grouping shows you invention overlap. Kind code collapsing shows you lifecycle clarity.
But alias matching shows you who’s actually doing what. Without it, your whole picture is fragmented.
And if you’re building your strategy on that picture—whether it’s for funding, market expansion, or competitive positioning—you need to know it’s accurate.
How PowerPatent De-Dupes at Scale—So You Don’t Have To
You’ve seen how messy patent data can get. Families scatter across countries.

Kind codes multiply the noise. Aliases hide the real players. Trying to clean all of that up manually is like solving a 10,000-piece puzzle in the dark.
That’s why PowerPatent was built from the ground up to handle this chaos for you—so you can focus on what matters: protecting your edge and moving fast.
De-Duping Isn’t an Afterthought—It’s Built In
Most patent tools bolt on de-duping as a side feature. PowerPatent bakes it into the core. Every reference you upload, search, or analyze gets cleaned, grouped, and matched in real time.
You don’t have to flag duplicates or merge records. It’s all handled for you behind the scenes.
This means you get cleaner lists. Fewer false positives. Sharper insights. No more clicking through five versions of the same filing to figure out what’s going on.
Smart Family Matching That Goes Beyond Priority Dates
Our system doesn’t just match families by date or title. It uses legal claims, filing paths, shared inventors, and priority logic to link filings across regions and formats—even when they’re filed years apart or look different on paper.
You get one clear family. One core invention. No more bouncing between systems to guess what belongs together.
Automated Kind Code Collapsing Across Jurisdictions
PowerPatent recognizes kind codes from every major patent office. It knows that US A1 and B2 might be stages of the same invention.
It understands how Japan, Europe, Korea, and China use different codes for grants, continuations, and amendments.
So instead of reviewing the same idea three times, you see just one clean record—complete, accurate, and up-to-date.
Alias Matching You Don’t Have to Babysit
We maintain a dynamic alias library that tracks how companies and inventors change names, switch entities, or rebrand.
That means when you track a competitor or monitor your own filings, you’re seeing the full picture—not fragments.
And because it updates automatically, you’re always current. No more chasing down name variants across spreadsheets or wondering if you missed a stealth filing.
It’s Not Just Clean Data. It’s Actionable Data.
When your references are de-duped and unified, your next step becomes obvious. You can file faster, without second-guessing. You can review competitor moves with total clarity.
You can present clean, defensible positions to investors, partners, or the patent office.
And if you’re building internal IP dashboards or analytics tools, PowerPatent becomes your clean data source. No more trying to filter, merge, or correct upstream chaos. You start with clarity—and stay there.
Action Step: Upload Once, Let PowerPatent Handle the Rest
If you’ve got a stack of references—old filings, search results, or competitor portfolios—just upload them to PowerPatent. The system will instantly group, match, and clean the data. What comes out isn’t just a list.
It’s a strategy-ready snapshot of what you need to know.
From there, you can annotate, compare, filter, and file—all from one clean interface.
This Is About More Than Just Saving Time
Yes, de-duping saves you hours. But more than that, it keeps you sharp. It protects you from bad assumptions. It helps you move fast without fear. It gives you the edge in a world where clean insight is everything.
And it means you can focus on building, innovating, and filing with confidence—without getting bogged down by the messy middle.
Final Thought: De-Duping Is the Foundation, Not the Feature
Strong IP starts with clarity. And clarity starts with clean data. That’s why PowerPatent doesn’t just help you write better patents. It helps you see your patent landscape clearly—before you commit resources, before you file, before you take that next step.

If you’re ready to stop drowning in duplicates, alias errors, and kind code noise—PowerPatent is your unfair advantage.
Explore how it works and get started today → https://powerpatent.com/how-it-works
Wrapping It Up
Patent data doesn’t need to be messy. And protecting your inventions doesn’t need to feel like detective work.
When you clean up families, collapse kind codes, and match aliases the right way, you don’t just get better-looking data—you get real clarity. The kind of clarity that helps you file faster, spot opportunities sooner, and build IP that actually protects your edge.